L’intelligence artificielle (IA) fait couler de l’encre sur LinuxFr.org (et ailleurs). Plusieurs personnes ont émis grosso-modo l’opinion : « j’essaie de suivre, mais c’est pas facile ».
Je continue donc ma petite revue de presse mensuelle. Disclaimer : presque aucun travail de recherche de ma part, je vais me contenter de faire un travail de sélection et de résumé sur le contenu hebdomadaire de Zvi Mowshowitz (qui est déjà une source secondaire). Tous les mots sont de moi (n’allez pas taper Zvi si je l’ai mal compris !), sauf pour les citations : dans ce cas-là, je me repose sur Claude pour le travail de traduction. Sur les citations, je vous conseille de lire l’anglais si vous pouvez: difficile de traduire correctement du jargon semi-technique. Claude s’en sort mieux que moi (pas très compliqué), mais pas toujours très bien.
Même politique éditoriale que Zvi : je n’essaierai pas d’être neutre et non-orienté dans la façon de tourner mes remarques et observations, mais j’essaie de l’être dans ce que je décide de sélectionner ou non.
Petit glossaire de termes introduits précédemment (en lien : quand ça a été introduit, que vous puissiez faire une recherche dans le contenu pour un contexte plus complet) :
We are introducing GPT‑5, our best AI system yet. GPT‑5 is a significant leap in intelligence over all our previous models, featuring state-of-the-art performance across coding, math, writing, health, visual perception, and more. It is a unified system that knows when to respond quickly and when to think longer to provide expert-level responses. GPT‑5 is available to all users, with Plus subscribers getting more usage, and Pro subscribers getting access to GPT‑5 pro, a version with extended reasoning for even more comprehensive and accurate answers.
Traduction :
Nous présentons GPT-5, notre meilleur système d'IA à ce jour. GPT-5 représente un bond significatif en intelligence par rapport à tous nos modèles précédents, offrant des performances de pointe en programmation, mathématiques, rédaction, santé, perception visuelle, et bien plus encore. Il s'agit d'un système unifié qui sait quand répondre rapidement et quand prendre plus de temps pour fournir des réponses de niveau expert. GPT-5 est disponible pour tous les utilisateurs, les abonnés Plus bénéficiant d'une utilisation accrue, et les abonnés Pro ayant accès à GPT-5 pro, une version avec un raisonnement étendu pour des réponses encore plus complètes et précises.
Comme à l’accoutumée chez OpenAI, le modèle est accompagné de sa System Card.
La musique est bien connue à présent : chacun tour à tour, les trois gros acteurs (OpenAI/Anthropic/Google DeepMind) sortent un nouveau modèle qui fait avancer l’état de l’art, prenant la première place… jusqu’à ce qu’un des deux autres la reprenne en sortant le sien. C’est au tour d’OpenAI avec GPT-5.
Le nom a suscité beaucoup d’espoirs et de déceptions, beaucoup anticipant un saut qualitatif du même type que le passage de GPT-3 à GPT-4. Ce qui n’est absolument pas le cas : techniquement parlant, le modèle aurait pu s’appeler o4, représentant une amélioration incrémentale relativement à o3. L’objectif affiché d’OpenAI, derrière cette dénomination, est double : premièrement, de clarifier une offre extrêmement brouillonne (4o/o3/o3-pro/4.1/4.5) en offrant une dénomination unique avec des variantes plus claires, et offrir un modèle bien plus proche de l’état de l’art aux utilisateurs gratuit de ChatGPT.
Les benchmarks et la plupart des retours le placent comme une légère avancée de l’état de l’art, sans être une révolution. L’évaluation de METR résume parfaitement la situation ; une amélioration qui était parfaitement prévisible juste en extrapolant les tendances existantes :
Une amélioration notable est sur le taux d’hallucinations. Rappelons que o3 avait été un des seuls modèles à voir son taux d’hallucinations augmenter relativement à son prédécesseur ; avec GPT-5, OpenAI semble avoir corrigé le tir :
Sur la sécurité des modèles, aucune nouveauté notable relativement à o3. Les mitigations relatives aux risques biologiques/chimiques sont toujours en place, et comme à l’accoutumé OpenAI a fait appel à divers organismes tiers pour mesurer les risques posés par le modèle dans différentes catégories.
Et comme à l’accoutumée, Pliny the Liberator a jailbreak le modèle en quelques heures.
À noter que sur ChatGPT, OpenAI comptait complètement retirer l’accès aux anciens modèles, mais est revenu sur sa décision suite aux retours de beaucoup d’utilisateurs préférant le style plus chaleureux de 4o.
Google Genie 3, Gemini 2.5 Flash Image et Gemini 2.5 Deep ThinkUn mois prolifique pour Google, qui publie trois nouveaux modèles / modes de fonctionnement.
Google Genie 3 est présenté comme un « World Model » (modèle du monde ?). À partir d’un prompt textuel, et d’actions de navigation de l’utilisateur, il génère en temps réel la vue de l’utilisateur, frame par frame (à la manière d’un jeu vidéo). Il n’y a pas de représentation explicite externe de l’état du monde : c’est le modèle qui se charge de garder une certaine cohérence d’une frame à l’autre (comme la persistance des objets). Au delà de la preuve de concept, l’objectif affiché est de créer des environnements d’entraînement virtuels pour la robotique.
Autre publication, celle de Gemini 2.5 Flash Image, le modèle de génération d’images de Google. S’il ne semble pas avancer l’état de l’art de manière générale, sa grande force semble être le suivi d’instructions (et de respect des références) pour l’édition d’images.
Le mois précédent, DeepMind avait reporté avoir décoché un score correspondant à une médaille d’or aux Olympiades Internationales de Mathématiques, une avancée permise notamment par une utilisation plus stratégique de la chaîne de pensée (et d’avancées correspondantes sur la partie entraînement par renforcement). Google publie une version plus rapide, moins coûteuse et moins performante (cette version n’obtient « que » un score correspondant à la médaille de bronze sur les mêmes Olympiades), sous la dénomination Gemini 2.5 Deep Think. Le modèle a sa propre System Card ; tout comme OpenAI et Anthropic, les capacités de ce modèle dans le domaine CBRN (biologie/nucléaire) a conduit Google à placer des gardes-fous supplémentaires pour empêcher des usages malveillants.
En vracOpenAI publie son premier (depuis GPT-2, en 2019) modèle open-weight, gpt-oss. Au niveau des performances, il se placerait dans le peloton de tête des modèles open-weight, en compagnie de DeepSeek, Kimi, Qwen, GLM et Gemma, c’est à dire à peu près au niveau de la génération précédente des modèles entièrement fermés (comme Sonnet 3.6) / des versions rapides de la génération actuelle (Gemini 2.5 flash, o3-mini). WeirdML propose une visualisation intéressante sur leur propre benchmark pour vous donner un ordre d’idée. Rien de novateur au niveau de l’architecture, OpenAI s’en tient à la recette (maintenant universelle dans les modèles open-weight) d’une mixture d’experts. gpt-oss vient en deux variantes, la version complète, gpt-oss 120B, et une version plus légère et rapide, 20B.
Google publie un rapport sur l’impact environnemental de l’utilisation de Gemini. Cela exclu l’entraînement, mais les auteurs tentent de prendre en compte des coûts précédemment ignorés. Le résultat : 0,24 Wh d’électricité et 2,76 mL d’eau (le rapport initial mentionne 0,26 mL, mais sans comptabiliser l’eau utilisée pour générer les 0,24 Wh d’électricité) pour le prompt median (et l’équivalent de 0,03g de carbone émit).
Anthropic publie une nouvelle version de Opus, Opus 4.1. Comme la numérotation l’indique, il s’agit d’améliorations mineures — apparemment, un peu plus d’entraînement sur les tâches « agentiques » (utilisation d’outil) pour rendre Opus plus efficace sur ce type de tâches.
Similairement, DeepSeek publie une mise à jour « mineure » de son IA, DeepSeek v3.1. Les benchmarks fournis par DeepSeek semblent montrer un grand bond en avant, mais les quelques retours et benchmarks tiers ne corroborent pas ces prétentions — il s’agit probablement d’une mise à jour relativement mineure, comme la numérotation semble l’indiquer.
Nouvelle évaluation de l’IA, Prophet Arena. L’objectif est de permettre à l’IA de placer des positions virtuelles sur des marchés de prédiction, et de regarder ses performances. L’avantage de cette approche est de rendre complètement impossible la stratégie de juste mémoriser lors de l’apprentissage et régurgiter lors de l’évaluation : tout tâche est par essence nouvelle (car portant sur le futur). De plus, les résultats des marchés de prédiction forment un comparatif avec des prédictions par des utilisateurs humains. Résultat : les modèles les plus avancés (GPT-5, o3 Gemini 2.5 pro et Grok 4) dépassent les êtres humains sur le score de calibration, mais aucun n’arrive à traduire ça en de meilleurs retours financiers.
Anthropic se prépare à lancer Claude for Chrome, un plugin pour Google Chrome permettant à Claude d’interagir avec votre navigateur, à vos risques et périls.
En parallèle, les discussions sur claude.ai seront maintenant par défaut utilisées pour l’entraînement des versions suivantes de Claude, sauf si l’utilisateur désactive un paramètre sur son compte. Anthropic gardera les conversations pendant 5 ans.
Une nouvelle évaluation intéressante : TextQuests, qui évalue les modèles sur des jeux d’aventure textuels tels que Zork I. Cela a l’avantage de réellement tester les capacités de planification/raisonnement des modèles hors du domaine d’entraînement typique (mathématiques/programmation), tout en restant dans le domaine textuel (au contraire des évaluations multimodales, qui ont l’inconvénient de trop lier les résultats aux capacités perceptuelles des modèles).
Nouvelle technique d’interprétation des modèles, Model Diff Amplification. Elle consiste à amplifier les différences entre le pré-entraînement et le post-entraînement au moment de la génération, afin d’éliciter des comportements rares causés par le post-entraînement, ou tout simplement utiliser cette technique très tôt dans le post-entraînement pour se donner une idée des conséquences (prévues ou non) du post-entraînement complet.
Dr. Chistoph Heilig, chercheur en littérature et études bibliques, s’intéressant beaucoup aux capacités littéraires de l’IA, se met en tête d’évaluer GPT-5. Il se retrouve extrêmement surpris par la médiocrité de la prose produite par le modèle. De manière plus surprenante, un modèle complètement différent (Opus 4.1) juge le résultat comme étant de bonne qualité. La théorie qu’il propose est que ChatGPT 5 a été entraîné à l’aide d’un juge IA, et a appris à exploiter des constructions « peu humaines » que les modèles jugent systématiquement comme étant signes de qualité.
En parallèle de la sortie de GPT-5, OpenAI publie un guide sur comment créer un prompt, et un outil d’optimisation des prompts.
Anthropic et OpenAI font une tentative de coopération, où l’équipe d’évaluation de la sécurité des modèles d’OpenAI évalue les modèles d’Anthropic avec leurs outils, et vice-versa. Aucune trouvaille surprenante (si ce n’est l’incapacité des deux équipes de détecter la flagornerie flagrante de 4o), mais le concept est intéressante.
xAI publie la version précédente de son IA, Grok 2, en open-weight.
Une étude d’Anthropic développe un moyen pour identifier un sous-ensemble d’un modèle associé à un « trait de personnalité » particulier. Cela permet d’amplifier ou de supprimer ce trait, ou encore de détecter son activation.
« L’IA a-t-elle la qualité de patient moral » (en d’autres termes : devons-nous tenir compte de son bien-être pour des raisons morales) ? Anthropic commence à prendre la question au sérieux, avec comme première décision de permettre à son IA, Claude, d’unilatéralement mettre fin à une conversation qu’il jugerait abusive.
GPT-5 finit Pokémon Rouge en trois fois moins de temps que o3. La réduction du taux d’hallucinations serait la principale source de ce gain de performances. Gemini a également terminé sa partie de Pokémon Jaune. Claude, par contre, peine toujours à aller plus loin que Celadon…
La Chine continue à appeler à la coopération internationale pour la régulation du développement de l’IA, que ce soit par la voix du premier ministre ou d’universitaires.
Lors du sommet sur l’intelligence artificielle de Seoul de 2024, la plupart des acteurs, incluant Google, s’étaient volontairement engagés à suivre certaines actions relatives à la sécurité des modèles. Essentiellement, ce que le plupart faisaient déjà : publier une politique de sécurité des modèles, et s’engager à la suivre. Google se trouve aujourd’hui critiqué pour ne pas avoir suivi ses propres engagements. En cause, la publication de Gemini 2.5 Pro sans sa System Card associée, qui est arrivée plusieurs semaines après la publication du modèle. Google se défend en affirmant que la publication était clairement mentionnée comme « expérimentale ».
Entraîner l’IA à être chaleureuse et empathique réduit ses performances.
Sur le sujet de la flagornerie de l’IA, un internaute s’attelle à une évaluation des différents modèles.
Le gouvernement Danois veut faire rentrer l’apparence physique et la voix dans le cadre du copyright afin de lutter contre les deepfakes.
Pour aller plus loinVoici d'autres ressources, qui n'ont pas été abordées dans cet article.
Par Zvi Mowshowitz :Commentaires : voir le flux Atom ouvrir dans le navigateur
Vous en souvient-il ? En deux mille vingt-cinq, qpad nous présentait Typst, un nouveau système de composition de documents qui se posait en concurrent de LaTeX.
Depuis, Typst semble avoir grandi, en s’assortissant d’une galaxie (pardon, un univers) de paquets tiers. En fait, j’ai surtout l’impression qu’il a gagné en notoriété, ou en quantité de mouvement, pour le dire comme les anglophones. C’est l’occasion de présenter à nouveau ce système de composition.
Typst est donc un système de composition de documents. Comme LaTeX, il est non-visuel, c’est-à-dire qu’on code son document qui est ensuite compilé en PDF.
Concrètement, l’outillage se compose, au choix :
Typst partage plusieurs caractéristiques avec LaTeX dont il est ouvertement inspiré :
Bien que je n’aie pas vérifié ce point, il me semble probable qu’il utilise également quelques algorithmes de mise en page assez incontournables, définis par Donald Knuth pour TeX, par exemple pour la coupure des lignes d’un paragraphe.
Il s’écarte évidemment de LaTeX sur plusieurs aspects, sinon ce ne serait pas vraiment un nouveau système de composition :
Quand on arrive de LaTeX, l’impression est assez partagée, entre des différences significatives, de gros avantages et quelques inconvénients.
Le langage de texteLe langage de base pour le texte est différent de LaTeX, mais ce n’est pas vraiment dérangeant dans la mesure où on parle seulement de paragraphes, de titres, de mise en emphase, de listes, etc. Bref, le genre de chose qu’on fait aussi bien en Markdown. D’ailleurs, Typst étant né après le développement des langages de balisage léger, sa syntaxe Typst est justement assez proche de Markdown, ce qui n’est pas désagréable :
= Titre de section Voici du texte avec _une emphase_, *une emphase forte* et un `peu de code`.À noter que cette syntaxe légère n’est en fait que du sucre syntaxique, et qu’on peut écrire la même chose en faisant explicitement appel à des fonctions nommées.
La compilationPour celles et ceux qui n’ont pas l’habitude de LaTeX, compiler un document un peu costaud, qui fait appel à quelques extensions, ça demande un temps de l’ordre d’une ou plusieurs secondes, et cela produit des centaines, voire des milliers de lignes de log. Pour avoir des références internes (sommaire, références à des images…) et externes (bibliographie), il faut lancer plusieurs fois la compilation.
Pour qui vient du monde LaTeX donc, la compilation par Typst est hallucinante. Une seule passe, même si en interne, Typst fait certainement au besoin plusieurs itérations. Quelques dizaines de millisecondes. Ok, c’était pour un document ultra-simple, mais les commentaires lisibles sur les Interwebz font généralement état d’un rapport d’un ou deux ordres de grandeur par rapport à LaTeX.
Le langage de configuration et d’extensionLà où ça change vraiment, c’est pour tout ce qui relève des réglages, des modèles, de la personnalisation ou de la programmation d’extensions. Là, ça n’a plus rien à voir avec TeX et LaTeX. À mon avis, ce n’est pas un mal dans la mesure où le langage TeX et les conventions utilisées pour le développement en LaTeX sont assez complexes, voire incompréhensibles.
Cela se ressent dans le code des extensions. À titre de comparaison, celui de la classe LaTeX lettre fait quelques milliers de lignes. Et c’est assez illisible pour qui ne connaît par TeX. Le code du modèle formalettre, qui n’est certes pas aussi complet mais qui fait très bien le travail de base d’une telle classe, fait une centaine de lignes, que je trouve relativement lisibles pour un béotien.
L’utilisation de paquets tiersLes paquets tiers, hébergés sur l’univers Typst, sont téléchargés à l’utilisation. Par rapport à une distribution LaTeX qui pèse facilement plusieurs centaines de mébioctets, ça donne une vraie impression de légèreté.
La francisationL’adaptation aux conventions en usage en langue française, ou dans les différents pays francophones, me semble encore assez incomplète.
Lorsqu’on passe un document en français, les changements de base s’effectuent bien : un sommaire s’appellera bien « Tables des matières » et les césures respecteront l’usage de la langue.
En revanche, cela n’adapte pas la mise en forme des paragraphes avec alinéa, et on attendrait en vain que des mots comme 1ᵉʳ, 2ᵉ ou Mme soient automatiquement mis en forme selon l’usage attendu. Et non, il n’y a pas de commandes définies pour cela. Pas encore, en tout cas, parce que je serais surpris que personne ne publie un jour un paquet proposant tout cela.
Les modèlesL’équivalent d’une classe LaTeX est un modèle Typst. Cela correspond à un type de document, par exemple un article, un rapport ou une lettre.
Typst ne semble pas proposer de modèles officiels. Il y en a en revanche par mal dans l’univers Typst, et le langage est conçu pour rendre la création d’un modèle assez accessible. Le troisième chapitre du tutoriel officiel traite justement de la création d’un modèle.
Un bel avenir ?Typst a été conçu à partir de 2019 et a vraiment vu le jour en 2023. J’en ai entendu parler pour la première fois en mars 2023, dans le journal de qpad.
Les lacunes que j’avais alors remarquées et qui me retenaient de commencer à l’utiliser pour mes propres documents, semblent avoir été comblées pour l’essentiel. L’univers Typst, qui est le dépôt de paquets tiers, s’est largement rempli et semble bien jouer son rôle pour permettre aux utilisateurs de partager les extensions et modèles.
Le langage semble bien conçu :
L’écosystème est également bien conçu et bien fourni et semble bien répondre aux attentes de la communauté, avec une légèreté bienvenue. Dans l’ensemble, j’ai l’impression que Typst est bien parti pour proposer un successeur sérieux à LaTeX. Je formule tout de même quelques interrogations :
Commentaires : voir le flux Atom ouvrir dans le navigateur
Cette revue de presse sur Internet fait partie du travail de veille mené par l’April dans le cadre de son action de défense et de promotion du logiciel libre. Les positions exposées dans les articles sont celles de leurs auteurs et ne rejoignent pas forcément celles de l’April.
Calendrier Web, regroupant des événements liés au Libre (logiciel, salon, atelier, install party, conférence), annoncés par leurs organisateurs. Voici un récapitulatif de la semaine à venir. Le détail de chacun de ces 26 événements (France: 26) est en seconde partie de dépêche.
L’Association Club Linux Nord Pas-de-Calais est présent tous les premiers mardis du mois aux Petites Cantines, à Croix.
Au cours de ces séances, nous vous proposons d’installer le système d’exploitation libre Linux et/ou les logiciels libres que vous utilisez sur votre ordinateur.
Si votre ordinateur est récent et que vous vous voulez vous donner les moyens de maîtriser les informations qui y entrent et en sortent, ou si votre ordinateur devient poussif…
Pensez à nous rendre visite, c’est gratuit et on vous donnera toutes les clés pour que vous puissiez faire le choix qui vous convient
The Document Foundation (TDF) est la fondation de droit allemand qui chapeaute le projet LibreOffice. Son directeur administratif, Florian Effenberg a rédigé une série d’articles sur le fonctionnement de TDF sur le site community.documentfoundation.org (EN) qui est, globalement, le site qui sert à informer la communauté sur TDF et la suite bureautique. Cet article porte sur la gestion administrative de la fondation.
Cette dépêche est une traduction de l’article de Florian, faite par Sophie Gautier (EN) aidée de DeepL et publiée ici avec leur autorisation et parce que ça me semblait intéressant pour mieux comprendre le fonctionnement de la fondation. J’ai gardé les liens originaux, sauf, dans le cas de liens vers Wikipédia, pour donner l’adresse en français quand elle existait et j’ai ajouté des notes qui m’ont paru nécessaires pour une meilleure compréhension.
Afin de mieux comprendre le fonctionnement de TDF et d’offrir plus de transparence et d’informations à la communauté, j’aimerais vous faire découvrir les coulisses de TDF et partager avec vous des informations complémentaires sur la fondation.
J’ai déjà commencé à partager des informations et des détails sur des tâches administratives spécifiques (EN), et je continuerai à y publier d’autres articles au fil du temps.
Ce texte décrit le fonctionnement actuel de TDF, notre structure, afin de vous aider à comprendre pourquoi et comment certaines choses fonctionnent (ou ne fonctionnent pas). Bien sûr, il s’agit du statu quo. J’ai quelques idées de changements et d’améliorations pour l’avenir, que je partagerai ultérieurement dans un message séparé.
Le défi consiste à trouver un équilibre entre l’amélioration de la structure générale de TDF, la réalisation de notre mission et la résolution des problèmes du passé. Si nous passons tout notre temps à améliorer notre structure, nous ne remplirons pas notre mission et ne réglerons pas les problèmes du passé. Et si nous ne trouvons pas le temps de nous attaquer aux problèmes difficiles du passé, cela pourrait également nous nuire.
Une fondation virtuelleThe Document Foundation est l’une des organisations libres et open source les plus importantes, et LibreOffice est l’un des projets de logiciels libres les plus reconnus.
On pense souvent que nous disposons de bureaux, d’infrastructures administratives, de salles de réunion et d’un espace de cotravail quelque part à Berlin. Certains cherchent même notre siège social, mais ne trouvent aucun de nous.
Cet article fait suite à : “L’architecture d’entreprise dans l’anthropocène : une stratégie numérique soutenable”. Le but de cette suite d’articles est d’essayer d’éclairer l’évolution du domaine métier de l’architecture d’entreprise sous le prisme de l’anthropocène.
En effet, au delà de la question de la soutenabilité, l’un des enjeux importants dans l’anthropocène, et peut-être le plus important, est la résilience de l’organisation.
Certaines entreprises ont déjà lancé des changements profonds avec le support du CEC (Convention des Entreprises pour le Climat) tandis que d’autres se lancent dans un exercice de propective pour définir la direction à suivre. A ce propos, le cabinet “Sinon Virgule” a d’ailleurs produit une excellente étude à la demande de la MACIF, La MAIF et la Caisse des dépôts sur le devenir de leur métier : “Peut-on assurer un monde qui s’effondre ?”.
La résilience d’un système numérique va bien au delà de la redondance matérielle et logicielle de ses systèmes.
En effet, dans le contexte géo-politique instable actuel, comme nous avons pu le voir pour la guerre en Ukraine avec l’explosion des coûts de l’énergie ou aujourd’hui avec l’augmentation du protectionnisme aux USA entraînant l’augmentation des taxes douanières, cette résilience implique un meilleur contrôle de ses infrastructures, ses technologies et ses données afin de s’assurer une certaine autonomie et indépendance vis à vis de ces évolutions géo-politiques.
Sur ce sujet de l’impact géo-politique, le CIGREF a d’ailleurs écrit une note intéressante très récemment : Géopolitique et stratégie numérique.
Au-delà des contraintes géopolitiques, l’usage du logiciel libre permet de lutter contre l’infobésité des géants de la tech pour soutenir votre stratégie de soutenabilité numérique mais aussi des impacts financiers de l’ajout de technologie comme l’IA générative qui ne vous apporteront peu ou pas de valeur métier mais juste à supporter la croissance des gafam dans le développement d’une technologie qui n’est pas encore mature (voir Gartner hype cycle).
Les raisons de passer aux logiciels libres sont vastes : géopolitique, souveraineté, autonomie numérique, … Et les exemples aussi :
Le logiciel libre ne se présente plus après plus de 40 ans d’existence. C’est devenu, en entreprise, un commun. Tout le monde s’y est mis même Microsoft qui luttait contre lui au début de son existence.
Regardons néanmoins, quelques grandes dates de l’écosystème du libre depuis les années 1970. Attention ce chronogramme n’est pas exhaustif. Pour avoir une vue complète, je vous invite à vous connecter au portail du logiciel libre sur Wikipédia :
Le logiciel libre s’est développé non grâce à une organisation type entreprise (cathédrale) mais par la coopération entre individus sans contre-partie financière hormis la reconnaissance de ses pairs : La cathédrale et le bazar.
En 40 ans, ce modèle d’intelligence collective a fournit des logiciels d’une telle qualité que ceux-ci sont devenus un standards dans un bon nombre de domaines.
Définition du logiciel libre :
Selon la Free Software Foundation, un logiciel est considéré comme « libre » s’il donne à l’utilisateur quatre libertés fondamentales :
L’essence du logiciel libre est donc une question d’éthique et de liberté des utilisateurs. Le logiciel libre tend à renforcer les droits de l’utilisateur.
L’Open Source Initiative (OSI) définit un logiciel open source comme un logiciel dont la licence respecte certains critères, principalement la libre redistribution du logiciel, l’accès au code source, la possibilité de créer des travaux dérivés et l’intégrité du code de l’auteur.
Quelques chiffres aujourd’hui :
Fondé en 2014, le groupement TODO propose un cadre pour construire un département dédier à l’open source dans une organisation, nommé OSPO : Open Source Programmme Office. TODO est une communauté de practiciens qui visent à créer les meilleures pratiques et outils pour opérer des OSPO dans les organisations.
Pour les moyennes et grandes organisations, une approche OSPO est intéressante. Un OSPO agit comme le point centralisé des activités open source d'une organisation, coordonnant les politiques d'utilisation, les stratégies de contribution, les procédures de conformité et les initiatives d'engagement communautaire.
Le mindmap proposé par TODO synthétise bien les capacités que l’OSPO peut porter :
Un programme d'opérations peut aider de nombreuses organisations à obtenir de meilleurs résultats grâce à l'open source comme le font déjà :
Avec quoi ?La liste des logiciels libre est longue, voici quelques bibliothèques répertoriant ceux-ci :
Pour donner une exemple concret, prenons 2 building blocks qui se retrouvent généralement dans les organisations : le poste de travail et l’ERP ou plutôt le PGI (progiciel de gestion intégré) en français.
Le poste de travail type bureautique avec des logiciels libres :
Les solutions sont nombreuses. On peut s’appuyer sur une solution pré-packagée comme openDesk mais qui nécessite une infrastructure kubernetes pour être exploitée. Une approche plus simple sera privilégiée pour les petites et moyennes organisations.
La suite openDesk, à ne pas confondre avec les meubles de bureau opendesk, a été financé par le Ministére fédéral Allemand de l’intérieur et du territoire afin de réduire la dépendance de l’administration publique des fournisseurs de logiciels propriétaires.
Cette suite comprend le socle de logiciels libres suivants :
Une solution plus légère pourrait se limiter à Cryptpad pour la partie Office et Nextcloud pour la partie workplace. Avec bien sûr un poste de travail tournant sur une distribution gnu-Linux comme Ubuntu avec Mozilla Firefox et Thunderbird en client lourd :
L'ERP avec les logiciels libres :
L’Enterprise Ressource Planning ou PGI, la solution est plus simple et plus complexe à la fois. Plus simple en terme de définition de la solution car une seule application embarquera l’ensemble des fonctionnalités et plus complexe à la fois car ces applications type ERP embarquent beaucoup de fonctionnalités et donc sont complexes à gérer.
L’organisation de grande taille préférera un ERP de type SAP ou Oracle E-busines suite, tandis que pour une petite ou moyenne structure le logiciel libre apporte de nombreuses solutions comme : ERPNext, Triton, Dolibarr, OpenConcerto, ….
Si nous prenons l’exemple de Dolibarr, les fonctionnalités couvertes sont les suivantes :
En conclusionDans l’anthropocène le logiciel libre est une excellente voie pour asseoir ou améliorer la résilience de son système d’information dans ce contexte géopolitique incertain et qui ne devrait pas s’améliorer (cf Tellus institute).
Les logiciels libres ne pourront certes pas supplanter toutes les applications de votre patrimoine applicatif mais pour ce qui existe pourquoi ne pas en profiter ? Regardez, même Microsoft est passé de “linux est un cancer” en 2001 à “Nous aimons linux” en 2014.
Les logiciels sont des logiciels d’excellente qualité comme ils l’ont déjà démontré. Le problème est peut être que les logiciels libres souffrent d’une image trop “tech”.
Au delà de cela, il existe aussi des applications métiers qui permettront de libérer une partie de votre SI :
Commentaires : voir le flux Atom ouvrir dans le navigateur
G’MIC, cadriciel libre pour le traitement des images numériques, vient de proposer une mise à jour significative, avec la sortie de sa nouvelle version 3.6.
Une bonne occasion pour nous de vous résumer les activités récentes autour de ce projet, et plus précisément, ce qu’il s’est passé depuis notre précédente dépêche, publiée il y a un peu plus d’un an (juin 2024).
N. D. A. : Cliquez sur les images pour en obtenir une version en pleine résolution, ou une vidéo correspondante lorsque les images contiennent l’icône
G’MIC (GREYC's Magic for Image Computing) est un projet libre dédié au traitement, la manipulation et la création d'images numériques. Il est développé principalement au sein de l’équipe IMAGE du laboratoire de recherche GREYC de Caen (laboratoire UMR, sous triple tutelle du CNRS, de l'ENSICAEN et de l'Université de Caen).
La base du projet repose sur un interpréteur de langage de script spécifique, le « langage G’MIC », pensé pour faciliter le prototypage rapide et l’implémentation d’algorithmes de traitement d’images. Autour de ce noyau viennent se greffer plusieurs interfaces utilisateur, qui donnent accès à des centaines d’opérateurs de traitement d’images, mais qui permettent également d’intégrer des pipelines de traitement personnalisés. G’MIC est donc conçu comme un cadriciel ouvert et extensible.
Parmi ses déclinaisons les plus utilisées, on retrouve : gmic, un outil en ligne de commande comparable et complémentaire à ImageMagick ou GraphicsMagick ; le service Web G’MIC Online ; et surtout le greffon G’MIC-Qt, intégrable dans de nombreux logiciels de création et d’édition d’images tels que GIMP, Krita, DigiKam, Paint.net, Adobe Photoshop ou Affinity Photo. Ce greffon est l’interface de G’MIC la plus populaire. Il donne aujourd’hui un accès rapide à plus de 640 filtres différents, élargissant considérablement les possibilités de filtres et d’effets offertes par ces logiciels de retouche d’images.
Fig. 1.1. Le greffon G’MIC-Qt en version 3.6, ici utilisé au sein de GIMP 2.10, avec le filtre « Paint With Brush » activé.
2. Les nouveautés du greffon G’MIC-Qt 2.1. Hommage à Sébastien Fourey, développeur de G’MIC-QtAvant de décrire la liste des nouveautés de cette version 3.6, nous souhaitons avant tout rendre hommage à notre collègue et ami, Sébastien Fourey, qui était maître de conférence à l’ENSICAEN et qui était le développeur principal du greffon G’MIC-Qt. Le 6 octobre 2024, Sébastien nous a quittés. Tous ceux qui le connaissaient vous le diront : Sébastien était avant tout une personne profondément humaine, généreuse et particulièrement attentive à tous ceux qui l’entouraient. Il était aussi discret et modeste qu’il était doué avec un clavier entre les mains (et c’était quelqu’un de très discret !).
Et même s’il n’a jamais voulu être mis au-devant de la scène, nous voulons ici faire une exception pour mettre en lumière son travail et le rôle majeur qu’il a eu dans le développement du projet G’MIC : c’est grâce à lui que G’MIC-Qt est aujourd’hui un greffon utilisé et apprécié par des milliers de personnes à travers le monde.
Il s’avère qu’il était un lecteur assidu de LinuxFr.org, et nous nous devions donc de lui rendre un hommage sur ce site. Sébastien nous manque profondément. Nous ferons notre possible pour que son œuvre perdure. Repose en paix, Sébastien ! Nous pensons à toi et à ta famille.
Fig. 2.1. Texte hommage à Sébastien Fourey, auteur de G’MIC-Qt, visible dans la section « About » du greffon.
2.2. Améliorations générales du greffonComme vous vous en doutez, le développement spécifique du greffon G’MIC-Qt a été à l’arrêt depuis octobre dernier. Néanmoins, les derniers ajouts de code réalisés sur le greffon ont rendu possible les choses suivantes :
Son code source est désormais compatible avec l’API de plug-in de la nouvelle version majeure de GIMP (la 3.0). Cela a permis d’offrir aux utilisateurs de GIMP un greffon G’MIC-Qt fonctionnel dès la sortie de GIMP 3. Notons qu’assez peu de greffons ont proposé une mise à jour à temps (Resynthesizer, greffon populaire, étant une autre exception). On remercie donc chaleureusement Nils Philippsen et Daniel Berrangé qui ont soumis les patchs activant cette compatibilité avec GIMP 3. Nous continuons en parallèle à maintenir notre greffon pour l’ancienne version (2.10) de GIMP, qui est encore beaucoup utilisée.
Le code de G’MIC-Qt devient également compatible avec l’API de la bibliothèque Qt6, la dernière version majeure en date de ce toolkit graphique.
L’interface du greffon propose maintenant un outil de prévisualisation des filtres avec séparateur intégré, de manière native. Cette fonctionnalité, accessible via le raccourci clavier CTRL + SHIFT + P, permet de comparer directement l’image avant et après l’application d’un filtre, en affichant les deux versions côte à côte dans la fenêtre de prévisualisation. Cette fonctionnalité existait déjà, mais elle est dorénavant utilisable de manière plus fluide, puisqu’auparavant elle était implémentée indépendamment par chaque filtre (le séparateur de prévisualisation était en fait vu comme un paramètre du filtre, ce qui impliquait un recalcul complet du résultat du filtre même lorsque l’on souhaitait seulement déplacer le séparateur).
Fig. 2.2.1. Prévisualisation native de filtres avec séparateur intégré dans G’MIC-Qt.
La vidéo suivante montre comment cette fonctionnalité améliorée se présente dans le greffon :
Fig. 2.2.2. Prévisualisation native de filtres avec séparateur intégré dans G’MIC-Qt (vidéo).
2.3. Nouveaux filtres d’imagesLes nouveautés principales du greffon G’MIC-Qt se matérialisent donc plutôt sous la forme de nouveaux filtres et effets accessibles pour les utilisateurs. À la sortie de cette version 3.6, c’est 640 filtres/effets différents qui sont proposés dans l’interface du greffon. En ce qui concerne le filtrage d’images, les dernières entrées ajoutées sont les suivantes :
Fig. 2.3.1. Le filtre « Deformations / Warp [RBF] » en action dans G’MIC-Qt.
La vidéo suivante montre son utilisation en pratique au sein du greffon G’MIC-Qt pour la déformation d’un visage :
Fig. 2.3.2. Le filtre « Deformations / Warp [RBF] » en action dans G’MIC-Qt (vidéo).
Fig. 2.3.3. Le filtre « Repair / Upscale [CNN2X] » en action dans G’MIC-Qt.
La figure suivante montre justement une comparaison des méthodes classiques d’agrandissement d’images, avec ce nouvel algorithme disponible dans G’MIC-Qt (résultat obtenu en bas à droite) :
Fig. 2.3.4. Comparaisons des méthodes d’agrandissement d’images avec notre nouvelle méthode « Upscale [CNN2X] ».
Notons que ce filtre illustre à lui seul quelques avancées récentes réalisées pour la nn_lib, qui est la petite bibliothèque interne d’apprentissage machine intégrée à G’MIC : Clipping des gradients, régularisation L2 des poids des réseaux, planificateur Cosine Annealing LR pour le taux d’apprentissage, module de Pixel Shuffling, sont quelques-unes des nouvelles fonctionnalités qui y ont été ajoutées. Cette bibliothèque de gestion de réseaux de neurones n’est pas très puissante (elle n’utilise que le calcul CPU, pas GPU), mais elle offre néanmoins la possibilité de créer des filtres intéressants basés sur des techniques d’apprentissage statistique.
Fig. 2.3.5. Le filtre « Degradations / VHS Filter » en action.
Ce filtre génère un bruit aléatoire, donc l’appliquer plusieurs fois sur une même image donne à chaque fois un rendu différent. On peut donc ainsi synthétiser de petites animations avec un look « analogique - années 90 » du plus bel effet. Les amateurs de Glitch Art apprécieront ! (voyez l’image originale à titre de comparaison).
Fig. 2.3.6. Le filtre « Degradations / VHS Filter » appliqué plusieurs fois sur une même image, pour en faire une séquence vidéo de type VHS.
2.4. Nouveaux effets de renduDe nouveaux effets font également leur apparition dans le greffon, non pas dans le but de modifier une image existante, mais pour créer une nouvelle image ou un motif à partir de zéro :
Fig. 2.4.1. Le filtre « Patterns / Organic Fibers » en action, avec deux jeux de paramètres différents.
Fig. 2.4.2. Le filtre « Rendering / Speech Bubble » permet d’ajouter des bulles de dialogue dans vos images.
La vidéo ci-dessous présente ce filtre en action dans le greffon G’MIC-Qt sur une photographie :
Fig. 2.4.3. Le filtre « Rendering / Speech Bubble » en action dans le greffon (vidéo).
Fig. 2.4.4. Le filtre « Rendering / 2.5D Extrusion » en action.
Fig. 2.4.5. Le filtre « Rendering / Fluffy Cloud » dans le greffon _G’MIC-Qt._
En jouant avec les différents paramètres du filtre, on peut obtenir des rendus variés et intéressants :
Fig. 2.4.6. Différents rendus de « Rendering / Fluffy Cloud » en faisant varier les paramètres du filtre.
Fig. 2.4.7. Trois exemples de motifs à rayures générés par le filtre « Patterns / Stripes ».
Fig. 2.4.8. Le filtre « Patterns / Gradient [from Curve] » extrait les couleurs d’une image localisées le long d’une courbe spline.
Fig. 2.4.9. Le filtre « Rendering / Neon Carpet », une contribution de Cli435.
Voilà pour ce qui concerne les nouveautés spécifiques au greffon G’MIC-Qt.
3. Améliorations du cœur du logiciel et de sa bibliothèque standardPassons maintenant à la description du travail réalisé cette année pour l’amélioration du cœur du projet, à savoir l’interpréteur G’MIC et sa bibliothèque standard d’opérateurs. Ce sont forcément des améliorations un peu moins visibles pour l’utilisateur final, mais elles sont toutes aussi importantes, car elles consolident ou améliorent des fonctionnalités qui peuvent ouvrir plus tard la porte au développement de nouveaux filtres originaux.
3.1. Optimisation de l’interpréteurLe moteur interne de G’MIC a bénéficié d’une série d’optimisations notables. Plusieurs améliorations internes, concernant l’analyse, la détection et la concaténation de chaînes de caractères ou encore la recherche de valeurs min/max dans de grandes images (désormais parallélisée avec OpenMP), ont permis d’augmenter légèrement les performances (gain moyen d’environ 2,5% sur le temps d’exécution de scripts G’MIC). Ce n’est pas un gain spectaculaire, mais ça se prend (et après 17 ans à écrire du code pour cet interpréteur, il aurait été presque inquiétant d’obtenir un gain beaucoup plus important !
Il y a exactement deux mois, un incident était survenu suite à un redémarrage brutal du serveur hébergeant les conteneurs de production et de développement ayant entraîné une attribution inattendue d’adresses IP. Et des réponses techniques 502 Bad Gateway pour notre lectorat.
Ce 26 août, vers 15:22, un message peu engageant est arrivé par pneumatique sur nos téléscripteurs (via Signal pour être précis) : « Tiens c’est bizarre j’ai perdu accès au site. Et au serveur oups. » L’après-midi et la soirée furent longues.
SommaireLe serveur répond au ping et permet les connexions TCP port 22, mais pas le SSH. Et les services web ne répondent plus. Souci matériel ? Noyau en vrac ? Attaque en cours ? Les spéculations vont bon train.
La connexion au serveur revient par intermittence, permettant à un moment d’exécuter quelques commandes, à d’autres d’attendre longuement pour l’affichage d’un caractère ou l’exécution de la commande tapée.
Le premier contact réétabli avec le serveur est assez clair (une forte charge) :
$ uptime 15:06:59 up 2 days, 2:54, 1 user, load average: 50,00, 205,21, 260,83(dernier redémarrage le week-end précédent, mais surtout une charge système moyenne respectivement de 50, 205 et 261 sur les 1, 5 et 15 dernières minutes)
Initialement on suppose qu’il s’agit d’un trop grand nombre de requêtes ou de certaines requêtes tentant des injections de code sur le site (bref le trafic de fond plutôt habituel et permanent), et on ajoute des règles de filtrage péniblement et lentement pour bloquer les IP qui ressortent le plus dans nos logs.
Le site est alors inaccessible pendant plusieurs périodes. On arrête et relance ensuite plusieurs fois les services en pensant avoir ajouté suffisamment de filtrage, mais rapidement le serveur se retrouve englué. Les services sont alors arrêtés plus longuement le temps d’analyser les logs au calme. Au calme inclut notamment ne pas juste disposer d’une connexion ssh depuis un smartphone, mais plutôt d’un clavier et d’un grand écran par exemple, de l’accès à tous les secrets et toute la documentation aussi.
Finalement le trafic n’est pas énorme (en volume total) et si les requêtes hostiles sont bien présentes, rien ne semble inhabituel. Par contre les processus de coloration syntaxique partent en vrille, consommant chacun un processeur et aspirant allègrement la mémoire disponible. Avant d’être éliminés par le noyau Linux.
La console est remplie d’élimination de processus de ce type :
Mais si rien n’a changé niveau logiciel sur le conteneur LXC de production et si les requêtes ne sont pas inhabituelles, qu’est-ce qui peut bien écrouler le serveur et créer ces processus gourmands ?
Eh bien des requêtes habituelles…Pendant les phases d’attente lorsque le serveur ne répondait plus vraiment, nous avons noté qu'une nouvelle entrée de suivi a été créée (merci BAud et merci RSS/Atom pour nous avoir permis de la voir alors que le serveur ne répondait déjà plus). Elle indique que la coloration syntaxique ne marche plus sur le site. Notamment l’exemple donné dans la documentation.
Pourtant le rendu fonctionne en testant en ligne de commande avec pygmentize.
Mais oui en testant l’exemple donné via le site, il est créé un processus Python2 pygment qui commence à se gaver de ressources.
Et en regardant les différents contenus et commentaires créés sur le site autour de l’incident, en filtrant sur ceux contenant des blocs avec de la coloration syntaxique, la dépêche (alors en préparation) sur G'MIC 3.6 apparaît. Et en testant cette dépêche, il est bien créé quatre processus Python2 pygment qui se gavent de ressources et ne semblent jamais vouloir se terminer. À rapprocher par exemple d’une page qui a été servie en 6785.9978s.
OK, le souci vient de requêtes tout à fait habituelles de coloration syntaxique, reste à comprendre pourquoi ces processus tournent mal.
La boucle sans finUn petit strace pour suivre les appels système en cours sur un des processus infernaux relève une boucle assez violente :
(...) close(623199355) = -1 EBADF (Bad file descriptor) close(623199356) = -1 EBADF (Bad file descriptor) close(623199357) = -1 EBADF (Bad file descriptor) (...)Il semble y avoir une immense itération sur des descripteurs de fichiers, en vue de les fermer, mais à l’aveugle, sans savoir s’ils existent réellement.
En regardant le code du composant utilisé (pygments), il semble n'y avoir qu'un seul appel à close() :
# close fd's inherited from the ruby parent import resource maxfd = resource.getrlimit(resource.RLIMIT_NOFILE)[1] if maxfd == resource.RLIM_INFINITY: maxfd = 65536 for fd in range(3, maxfd): try: os.close(fd) except: passDonc on itère sur tous les descripteurs entre 3 et le maximum déterminé…
>>> import resource >>> print(resource.getrlimit(resource.RLIMIT_NOFILE)[1]) 524288 >>> print(resource.RLIM_INFINITY) -1Un demi-million de fois ici donc. L’objectif initial de la boucle est de fermer les descripteurs de fichiers provenant du processus Ruby père, issue du fork via Open3.popen3. La version suivante du composant la remplace d’ailleurs par un ajout de l'option :close_others, qui précisément « modifie l’héritage [des descripteurs de fichiers du processus parent] en fermant les non-standards (numéros 3 et plus grands) ».
Sur une Debian 12, la limite du nombre de fichiers par défaut, c’est 1 048 576. C’est déjà probablement bien plus que la valeur qui prévalait à l’époque où a été écrit la boucle Python (on avait des limitations à 4096 à une époque reculée). Mais il s’avère que durant le week-end l’hôte du conteneur de production a été migré en Debian 13. Sans modification du conteneur de production pensions-nous. Sans modification directe du conteneur de production. Mais quid d’une modification indirecte ? Par exemple si la limite par défaut des « Max open files » était passée à 1 073 741 816 sur l’hôte, soit 1024 fois plus que quelques jours auparavant. Et donc des boucles nettement plus longues voire sans fin, sans libération de mémoire.
On ne peut mettre à jour le composant pygments dans l’immédiat, mais on peut limiter les dégâts en abaissant la limite du nombre de descripteurs de fichiers à quelque chose de raisonnable (i.e. on va gaspiller raisonnablement des cycles CPU dans une boucle un peu inutile mais brève…). Une édition de /etc/security/limits.conf, un redémarrage du conteneur de production et on peut vérifier que cela va nettement mieux avec cette réparation de fortune.
Une dernière page d’epub ?Le conteneur LXC portant le service epub de production a assez mal pris la surcharge du serveur, et vers 20h08, systemd-networkd sifflera la fin de la récré avec un eth0: The interface entered the failed state frequently, refusing to reconfigure it automatically (quelque chose comme « ça n’arrête pas d’échouer, débrouillez-vous sans moi »). Le service epub est resté en carafe jusqu’au 27 août vers 13h31 (merci pour l’entrée de suivi).
Voir ce commentaire sur la dépêche de l’incident précédent expliquant la séparation du service epub et du conteneur principal de production (en bref : dette technique et migration en cours).
Retour en graphiques sur la journéeLe serveur était très occupé. Au point de n’avoir pas le temps de mettre à jour les graphiques de temps en temps.
Rétrospectivement les processeurs du serveur ont travaillé dur : 140 de charge sur le graphique (mais avec des pics jusque 260 d’après la commande uptime), contre moins de 5 en temps normal (un petit facteur de 28 à 52 ô_Ô)
Et l’utilisation de la mémoire montre aussi de brutaux changements de comportement : libération intempestive de mémoire (Free, en vert), utilisation mémoire plus importante que d’habitude (Used, en jaune), là où le comportement normal est d’avoir le maximum en cache (Cached, en orange) et des processus tellement peu consommateurs en RAM que cela n’apparaît normalement pas.
Mesures préventives et correctivesDans les actions en cours ou à prévoir :
De façon cocasse, ce nouvel incident et le temps passé à parcourir les différents logs ont permis de retrouver les infos de la carte d’administration distante et d’expliciter l’origine du redémarrage serveur intempestif. À quelque chose malheur est bon, si on peut dire. Ceci n’est pas une invitation pour un prochain incident.
Télécharger ce contenu au format EPUBCommentaires : voir le flux Atom ouvrir dans le navigateur
Haiku est un système d’exploitation pensé pour les ordinateurs de bureau. Il est basé sur BeOS mais propose aujourd’hui une implémentation modernisée, performante, et qui conserve les idées qui rendaient BeOS intéressant: une interface intuitive mais permettant une utilisation avancée, une API unifiée et cohérente, et une priorisation de l’interface graphique par rapport à la ligne de commande pour l’administration du système.
Le projet est actuellement (depuis 2021) en phase de beta test. La plupart des fonctionnalités sont implémentées et l’attention des développeurs se porte sur la correction de bugs, l’amélioration de la stabilité et des performances, et plus généralement, les finitions et petits détails. Une autre part du travail est le suivi de l’évolution de l’environnement technologique: nouveaux pilotes de périphériques, suivi des derniers standards du web, etc.
Les trois derniers mois ont été un peu plus calmes que d’habitude pour Haiku, mais cela est largement compensé par une très forte activité du côté de Haikuports. Cela révèle que le système lui-même devient plus mature et qu’il devient de plus en plus facile de développer ou de porter une application sans tomber sur des problèmes du système qui doivent être corrigés au préalable.
Tracker est le navigateur de fichiers de Haiku. Le code est hérité directement de BeOS (cette partie avait été publiée sous licence libre lors de l’abandon de BeOS par Be) et fait l’objet depuis de nombreuses années d’un gros travail de nettoyage et de modernisation.
Pas de grosses nouveautés ces derniers mois, mais des corrections pour plusieurs régressions suites à du nettoyage effectué précédemment. Par exemple, les icônes des disques montés sont à nouveaux affichés sur le bureau dans les dialogues d’ouverture et d’enregistrement de fichiers. L’annulation du filtrage du contenu d’un dossier en tapant un nom de fichier partiel est correctement annulé si on appuie sur échap.
Enfin, des problèmes de synchronisation de l’icône de la poubelle, qui apparaissait pleine alors qu’elle était vide, ont été corrigés. Ces problèmes étaient déjà présents dans BeOS.
TerminalLe terminal permet de lancer des applications en ligne de commande.
Un chantier en cours consiste à rendre le terminal utilisable comme un “replicant”, c’est-à-dire de pouvoir l’intégrer dans d’autres applications telles que l’IDE Genio. Cette approche demande de restructurer beaucoup de choses, et pour l’instant, il est plus simple pour les développeurs de Genio de recopier une partie des sources du Terminal dans leur projet et de les intégrer de façon plus statique. Les problèmes sont corrigés petit à petit.
Une autre correction mérite d’être mentionnée: le terminal se plaçait lui-même dans le dossier de travail du shell lancé lors de l’ouverture d’un nouvel onglet. Si ce dossier se trouve dans un disque qu’on essaie par la suite de démonter, le démontage échoue (même si l’application lancée dans le terminal a elle-même changé de dossier entretemps). Désormais le terminal ne modifie pas son dossier actif et ne bloque plus le démontage des disques.
MailL’application Mail permet de lire et d’envoyer du courrier électronique. Elle est composée d’un serveur de synchronisation et d’une interface graphique indépendante. Entre les deux, les mails sont stockés sous forme de fichiers augmentés d’attributs étendus, ce qui permet d’utiliser Tracker et les requêtes BFS comme outil principal pour traiter les messages.
Les changements listés ici concernent l’application de lecture et rédaction de messages:
Correction du comportement du menu « Fermer et marquer comme… » lorsqu’il est appliqué à plusieurs messages.
HaikuDepot est à la fois le gestionnaire de paquets et le magasin d’applications de Haiku. Ce double rôle conduit pour l’instant à une interface qui prête un peu à confusion, et l’interface devrait être repensée pour un fonctionnement plus intuitif. En attendant, quelques petites améliorations ont tout de même été faites pour rendre les problèmes moins gênants.
Lorsqu’une recherche dans la vue « paquets mis en avant » ne donne aucun résultat, il y a affichage d’un lien permettant de poursuivre la recherche dans la liste complète des paquets. En effet, de nombreux utilisateurs se sont plaints de ne pas trouver certains logiciels en effectuant une recherche, sans se rendre compte qu’ils faisaient une recherche dans une liste de quelques dizaines de paquets et pas dans tout ce qui est disponible.
TextSearchTextSearch est un outil de recherche dans le contenu des fichiers par expressions régulières (une version graphique de grep).
Il reçoit ce trimestre une fonction pour filtrer les fichiers à rechercher, équivalent à l’option grep --include.
Debug AnalyzerDebug Analyzer est un outil de profiling et d’analyse de traces d’exécution.
Correction d’un problème de compilation suite à des changements dans l’API de BObjectList (cet outil n’est pas compilé par défaut, il avait donc été oublié lors du changement d’API au trimestre précédent).
Préférences d’apparenceDans la configuration des couleurs du système, renommage de la couleur « barre d’état » en « barre de progression ». Le nom « barre d’état » (status bar en anglais) correspond à la classe BStatusBar utilisée par BeOS et Haiku, mais tout le monde appelle ça une barre de progression. On peut au moins éviter la confusion pour les utilisateurs, à défaut de pouvoir le faire pour les développeurs d’applications en renommant la classe elle-même (ce qui causerait des problèmes de compatibilité d’API et d’ABI).
Utilisation de IconMenuItemCe changement concerne l’application ShowImage (visualiseur d’images) ainsi que FileTypes (les préférences d’association de types fichiers avec des applications). Ces deux applications utilisent un menu pour sélectionner une application (pour ouvrir une image dans un éditeur, ou pour associer un type de fichier à une application, respectivement).
Les applications pour Haiku utilisant des icônes colorées et facilement identifiables, c’est beaucoup mieux qu’une liste de noms pour s’y retrouver rapidement. Ces deux applications utilisent donc maintenant des IconMenuItem dans ces menus, pour afficher les applications avec leur icône respective.
Adaptation aux écrans à très haute réolutionUn travail en cours sur les applications concerne l’adaptation aux écrans à très haute résolution.
Presque toutes les applications pour Haiku utilisent un système de mise en page dynamique, et toutes les ressources (police de caractères, icônes…) sont vectorielles. Cela permet en théorie d’afficher l’interface avec un niveau de zoom arbitraire. Cependant, une partie du code a été écrit avec des tailles en pixels « en dur » et ne s’adapte pas comme il faudrait (la bonne façon de faire est de se baser par exemple sur la taille de la police de caractères sélectionnée par l’utilisateur).
Ce trimestre, on trouve des évolutions à ce sujet dans plusieurs applications:
L’outil de connexion au bureau à distance n’est pas vraiment une application en ligne de commande. Cependant, il nécessite pour l’instant un lancement depuis un terminal avec les bonnes options, et selon les cas, la mise en place d’un tunnel SSH. Une interface grapique plus simple d’uitlisation sera probablement ajoutée plus tard.
Le panneau de préférences de date et heure peut être lancé en ligne de commande avec une option spécifique pour forcer une synchronisation NTP. Cette fonctionnalité n’est pas vraiment documentée, à l’origine il s’agit plutôt d’une astuce interne au système. L’application reconnaît maintenant l’option --help standardisée et affiche un message d’aide qui documente cette fonctionnalité.
Il peut être utile de relancer cette commande manuellement si jamais la synchronisation au démarrage n’a pas fonctionné (par exemple si le réseau n’était pas disponible à ce moment-là). En particulier, cela peut être utilisé dans des scripts d’automatisation et pour des machines où l’interface graphique n’est pas facilement accessible (serveurs de build par exemple).
pkgmanpkgman est une commande permettant d’installer, mettre à jour et rechercher des paquets logiciels.
Ajout d’une option --no-refresh pour ne pas retélécharger la base de données des paquets.
Cette base de données contient non seulement les noms des paquets, mais aussi leur description courte et la liste des “provides” (par exemple: commandes et bibliothèques fournies par chaque paquet). pkgman vérifié déjà si une nouvelle version de la base de données est disponible, mais cette dernière peut être mise à jour plusieurs fois par jour par l’intégration continue.
Le nombre de paquets augmentant, la taille de la base de données devient non négligeable (plusieurs méga-octets), ce qui pose problème en particulier pour les utilisateurs et développeurs ne disposant pas d’un accès internet illimité.
suLa commande su est peu utilisée puisque l’utilisateur par défaut a déjà tous les droits. Son implémentation était donc un peu incomplète. Elle peut toutefois être utile pour avoir des utilisateurs supplémentaires restraints, par exemple pour un accès à distance par ssh.
listarea est une commande de debug permettant de lister les zones mémoire allouées à différentes applications. Elle affiche maintenant le verrouillage et les protections de ces zones (swappable ou non, exécutabele ou non, accessible en écriture ou non).
fdinfofdinfo permet d’examiner les descripteurs de fichiers ouverts (un peu comme lsof). Cette commande peut maintenant afficher en plus le dossier courant de chaque application (ce qui aurait été bien utile pour identifier le problème avec le dossier courant du Terminal ci-dessus).
install-wifi-firmwaresCe script permet d’installer les firmwares pour certaines très anciennes cartes Wifi. Les firmwares publiés à l’époque sont disponibles avec des licenses n’autorisant pas la redistribution ou les modifications de packaging, ce qui empêche l’intégration dans le système de paquets habituel. Le problème a été corrigé depuis longtemps par les fabricants de cartes Wifi, mais les anciens firmwares n’ont jamais été republiés avec des licenses mises à jour.
Le script a été mis à jour pour récupérer certains firmwares depuis un nouveau serveur, l’ancien emplacement utilisé n’étant plus disponible.
KitsLa bibliothèque de fonctions de Haiku est découpée en kits qui regroupent des ensembles de fonctions et de classes par thématique (stockage sur disque, interface graphique…). Dans certains cas il s’agit principalement d’une méthode d’organisation du code source et de la documentation (les kits pouvent être très interdépendants). Certains kits sont toutefois fournis sous forme de bibliothèques séparées.
Support kitCe kit contient diverses fonctions utilitaires et basiques du système.
Changement d’API pour la classe BUrl. Dans l’ancienne version de cette classe, il était possible de construire un objet BUrl représentant une URL encodée ou non-encodée (échappement des caractères réservés). Cela rendait trop facile d’oublier d’encoder une URL avant de l’utiliser, ou bien d’encoder plusieurs fois une URL et de se retrouver avec un lien invalide.
La nouvelle API impose d’indiquer dès la création d’un objet BUrl si la chaîne de caractères servant de base est déjà encodée ou non. L’objet BUrl construit représentera toujours une URL déjà encodée, qui peut éventuellement être décodée pour affichage si nécessaire.
Interface kitCe kit contient tout ce qui se rapporte à l’interface graphique: fenêtres, vues, contrôles, mise en page…
Retour en arrière sur une modification des raccourcis claviers de BTextView pour naviguer vers les mots suivant et précédent. Les nouveaux raccourcis entrent en conflit avec des raccourcis déjà utilisés par plusieurs applications, et n’apportaient pas grand-chose.
Correction de problèmes de compatibilité dans le format des données stockées par la classe BPicture (il s’agit d’un enregistrement de commandes envoyées au serveur graphique, qui peuvent être rejouées plus tard). Le format des données stockées était différent de celui de BeOS. Certaines applications utilisant un objet BPicture enregistré dans une ressource de l’application, ne s’affichaient pas correctement.
Amélioration de la gestion des sous-menus, en particulier cela corrige un crash si un sous-menu est fermé en utilisant la touche échap.
Remise à plat de tous les calculs accumulés au cours des années pour générer les couleurs de l’interface graphique en fonction des couleurs choisies par l’utilisateur. Chaque morceau de code concernait faisait ses propres calculs pour générer de jolis dégradés, des variantes plus sombres et plus claires, etc. Cela fonctionnait bien avec le thème par défaut, mais pas forcément avec des choix de couleurs qui en sont très éloignés. Le nouveau code est plus simple, plus prédictible, et permet de rassembler ces calculs dans la classe « control look », qui peut être remplacée par un add-on pour fournir une apparence complètement différente.
Cela peut nécessiter d’ajuster un peu les couleurs dans les préférences d’apparence si vous les avez personnalisées.
Storage kitCe kit regroupe tout ce qui concerne le stockage de masse et la gestion des fichiers.
Harmonisation de la nouvelle fonction BQuery::SetFlags avec d’autres fonctions similaires, et ajout d’une page de documentation pour cette fonction.
Correction d’un crash lorsqu’on enregistre un type MIME alors que le type parent n’existe pas (par exemple si on enregistre image/gif alors que le type image n’existe pas).
Ajout d’une constante pour identifier les systèmes de fichiers FAT16 parmi la liste des systèmes de fichiers connus.
Shared kitLe shared kit contient des fonctions expérimentales en cours de développement mais déjà utilisées par plusieurs applications.
Contrairement aux autres kits, il est fourni sous forme d’une bibliothèque statique, ainsi chaque application peut en utiliser une version différente (choisie au moment de la compilation) et il n’y a pas de contraintes pour conserver une stabilité d’API ou d’ABI. Les fonctions développées dans le shared kit peuvent ensuite être migrées vers les autres kits une fois qu’elles sont finalisées.
La classe « color list » (utilisée par exemple dans les préférences d’apparence) accepte maintenant le glisser-déposer de couleurs.
ServeursLes serveurs sont des applications lancées au démarrage du système. Ils sont similaires aux services systemd. Ils fournissent des services utiles à l’implémentation de la bibliothèque standard, car tout ne peut pas être fait dans une bibliothèque partagée.
app_serverapp_server regroupe le serveur graphique de Haiku (utilisé au travers de l’interface kit) ainsi que la gestion des applications en lien avec l’application kit.
Correction d’un problème d’initialisation de variables indiquant dans quels workspaces (bureaux virtuels) une fenêtre doit être présente. Cela se manifestait par l’apparition de morceaux incomplets de la fenêtre si on change de bureau virtuel pendant son apparition. Le bug existait depuis 15 ans mais n’avait jusque-là pas pu être identifié.
Les curseurs de souris ne sont plus générés en bitmap à la compilation à partir des sources vectorielles. C’est maintenant fait lors de l’initialisation du serveur graphique, ce qui permet d’avoir un plus gros curseur sur les écrans à très haute résolution.
input_serverinput_server se charge des périphériques d’entrée utilisateurs (claviers, souris et autres périphériques de saisie et de pointage).
Correction de la keymap espagnole latino-américaine dans laquelle plusieurs combinaisons de touches ne fonctionnaient pas comme sur les autres systèmes.
Pilotes ACPI, gestion d’énergie, systèmeMise à jour de ACPICA pour la prise en charge de ACPI avec la dernière version disponible.
Correction de problèmes dans le pilote poke (permettant l’accès direct à la mémoire pour écrire certains pilotes en espace utilisateur) pour mieux valider les paramètres des ioctl et éviter de pouvoir facilement déclencher un kernel panic suite à une mauvaise utilisation du pilote.
RéseauCorrection d’un problème dans la pile TCP ou les retransmissions de paquets lors de l’établissement de la connexion n’étaient pas faits, si le premier paquet était perdu, la connexion ne s’établissait jamais.
Lorsque IP_HDRINCL est activé (une application demande à envoyer et recevoir elle-même les en-têtes IP des paquets reçus), la pile réseau s’assure tout de même que les en-têtes générés ont bien un checksum valide. Cela permet à traceroute de fonctionner correctement par exemple.
Mise en place de l’infrastructure pour la découverte de MTU deu chemin. Cela permet de déterminer la taille maximale des paquets qu’on peut envoyer vers un serveur, sans que de la fragmentation IP soit mise en jeu en cours de route (ce qui, au mieux dégraderait les performances, au pire empêcherait la connexion de fonctionner correctement):
Cela permet déjà de détecter les problèmes de MTU, mais pas encore de les corriger automatiquement. La suite du code est encore en cours de test.
Remplacement du pilote iprowifi3945 par la version mise à jour disponible dans OpenBSD (pilote “wpi”) à la place de celle de FreeBSD qui est actuellement moins bien maintenue.
Interface homme-machineAjout de la tablette Intuos 4 dans le pilote pour les tablettes Wacom, ainsi que du support de la molette présente sur certaines tablettes.
Systèmes de fichiers NFS4NFS est un système de fichier en réseau. Une machine serveur se charge réellement du stockage des fichiers, et d’autres machines peuvent monter ce disque et accéder aux fichiers partagés. Plusieurs machines peuvent accéder au même serveur en même temps et modifier les fichiers, ce qui nécessite une attention particulière lors de l’implémentation d’un système de fichier client.
Le travail sur le pilote NFSv4 se poursuit pour le stabiliser et améliorer sa compatibilité avec les serveurs NFS existants.
Correction de problèmes de gestion du cache et de libération anticipée d’inodes`, points sur lesquels NFS est un peu inhabituel par rapport à d’autres systèmes de fichiers puisque des évènements peuvent arriver du serveur NFS concernant un fichier qui a été supprimé localement, par exemple.
Correction d’un problème qui pouvait conduire un fichier nouvellement redimensionné à contenir des données non initialisées au lieu d’octets à 0.
Cela permet de corriger des problèmes détectés par des tests NFSv4 existants pour d’autres systèmes.
EXT4Le pilote ext4 permet de monter, en lecture et en écriture, les systèmes de fichiers ext2, ext3 et ext4 développés pour Linux.
Implémentation et activation de la fonctionnalité « metadata_csum_seed » qui est activée par défaut pour les systèmes de fichiers nouvellement créés sous Linux.
Corrections dans le « tree splitting » qui n’était pas implémenté correctement, empêchant d’accéder à des dossiers contenant un trop grand nombre de fichiers.
RAMFSRAMFS est un système de fichiers non persistant, stockant les fichiers uniquement dans la RAM. Il est plus rapide qu’un système de fichier traditionnel.
Correction de crashs lors de la création de gros fichiers et lors du remplacement d’un hardlink par un autre fichier.
FATFAT est un système de fichiers développé par Microsoft pour DOS et les anciennes versions de Windows. Il est assez répandu et sert un peu de format d’échange standard en particulier pour les supports de stockage externes (clés USB, cartes SD, disquettes…).
Ajout d’assertions et de vérifications d’intégrité supplémentaires. Le pilote FAT utilisé actuellement provient de FreeBSD, dont les développeurs nous ont assuré qu’il était bien testé et maintenu. Mais, de façon similaire aux pilotes Wifi, on se rend compte que les bases d’utilisateurs de Haiku et de BSD ne sont pas du tout les mêmes, et nous sommes face à beaucoup de systèmes de fichiers FAT corrompus ou inhabituels, ce qui se produit peut-être moins souvent dans les utilisations de FreeBSD sur un serveur par exemple.
librootLa libroot contient l’équivalent de la libc, libdl, libpthread et libm d’un système UNIX standard, ainsi que des fonctions bas niveau spécifiques à BeOS.
Les extensions GNU et BSD sont déportées dans des bibliothèques séparées (libgnu et libbsd), ce qui permet de respecter au mieux la spécification POSIX sans avoir à utiliser des astuces telles que des « weak symbols ».
Mise à jour de la libioLa bibliothèque standard de Haiku est à l’origine un fork de la glibc, utilisant exactement la même version que BeOS afin de garantir une compatibilité d’ABI optimale avec ce dernier. Cependant, cette version ancienne et obsolète ne répond pas aux besoins des applications modernes.
Petit à petit, des parties de la bibliothèque C sont donc remplacées par des composants venant de FreeBSD, NetBSD, OpenBSD ou plus récemment de musl. Certaines choses sont très bien standardisées et ne posent pas de problèmes, pour d’autres parties, des symboles internes de la bibliothèque sont exposés et parfois exploités par des applications (directement par des développeurs applicatifs pour contourner un bug, ou alors parce que les développeurs de la glibc ont mal isolé les choses et ont exposé des détails internes).
Ce trimestre, la partie libio (gestion des flux d’entrée-sortie) a été mise à jour avec la dernière version de la glibc. Il n’est pas possible d’utiliser une autre bibliothèque C pour cette partie sans casser l’ABI, mais la mise à jour est possible.
Correction de multiples problèmes dans les fonctions standard C et les extensions BSD:Ajout d’une vérification de la locale passée à setlocale pour retourner une erreur si la locale demandée est invalide.
L’ouverture d’un chemin se finissant par un / avec open() échoue si le fichier n’est pas un dossier (par exemple open("/home/user/foo.txt/")).
Validation du paramètre “how” de la fonction shutdown() et retour d’une erreur si le paramètre n’est pas une valeur connue.
Les queues d’évènement créées par kqueue ne sont pas conservées lors d’un fork (même comportement que les BSD).
Un socket sur lequel il n’y a jamais eu d’appel à listen() ou connect() ne doit pas déclencher les erreurs EPIPE ni ENOTCONN.
La fonction socket() retourne maintenant les bons codes d’erreurs détaillés si elle ne peut pas créer le socket: EPROTOTYPE si le type de protocole est inconnu, EPROTONOSUPPORT s’il est connu mais pas disponible, EAFNOSUPPORT si la famille d’adresse n’est pas disponible. Auparavant, tous ces cas renvoyaient EAFNOSUPPORT.
Amélioration de la gestion des erreurs dans accept()
Gestion de cas particuliers pour bind() en UDP
Ajout de l’option RTLD_GROUP pour dlopen(). Il s’agit d’une extension développée par Solaris qui permet d’avoir plusieurs espaces de noms pour la résolution de symboles lors du chargement de bibliothèques partagées. En particulier, dosemu l’utilise pour fournir aux programmes DOS une bibliothèque C indépendante de celle de l’hôte (fournissant donc des fonctions memcpy, memset… qui entreraient en conflit avec celles de l’hôte). L’implémentation est triviale, car le même comportement était déjà en place pour la gestion des add-ons de BeOS; il n’était simplement pas accessible au travers de l’API POSIX dlopen(). Linux implémente ce flag sous un autre nom, cependant, la documentation de la glibc n’est pas correcte, et FreeBSD a implémenté ce qui est documenté pour la glibc avec le même nom. C’est pourquoi le nom utilisé par Solaris, qui n’est pas ambigu, est utilisé pour l’instant, en espérant que la méprise entre Linux et FreeBSD pourra être corrigée.
sethostname() retourne une erreur si le hostname proposé est trop long (auparavant il était simplement tronqué).
La spécification POSIX a été mise à jour en 2024. Cette mise à jour est assez importante grâce à un changement de la méthode de travail de l’Austin Group qui maintient la spéficication. Le groupe de travail a ouvert un bug tracker sur lequel il est possible de remonter des problèmes et de proposer des améliorations (à conditions que ces dernières soient déjà implémentées sous forme d’extensions sur un assez grand nombre de systèmes).
Cela a permis à plus de monde de prendre part à la spécification et de standardiser beaucoup de nouvelles choses. Haiku intègre ces changements petits à petits, parfois par anticipation, parfois parce que l’extension correspondante était déjà disponible, et parfois parce que le portage d’un logiciel le nécessite.
La gestion de la mémoire est un sujet central pour un système POSIX. L’API proposée (malloc, realloc, calloc et free) est à la fois très simple d’utilisation et très générique. Elle a donc tendance à être très sollicitée par les applications, ce qui en fait un composant critique de l’optilisation des performances du système. De plus, les applications sont de plus en plus consommatrices de mémoire et le matériel a tendance à en contenir de plus en plus.
L’allocateur mémoire a été remplacé il y a quelques mois, l’ancien allocateur hoard2 ne permettant pas d’agrandir dynamiquement l’espace alloué à une application. Après plusieurs essais, c’est pour l’instant l’allocateur d’OpenBSD qui a été retenu. En effet, beaucoup d’allocateurs plus modernes supposent un espace d’adressage 64 bit et sont peu économes en termes de réservation d’espace mémoire.
Cependant, même l’allocateur d’OpenBSD montrait ses limites sur les systèmes 32 bit. Son paramétrage a été amélioré, et d’autres modifications ont également été faites pour réduire la fragmentation de l’espace mémoire. Cela corrige des problèmes ou GCC ne parvient pas à allouer assez de mémoire lors de la compilation de très gros fichiers (par exemple lors de la compilation de clang ou de webkit). Il reste recommandé de désactiver l’ASLR (randomization de l’espace d’adressage) dans les cas où on a besoin de beaucoup de mémoire pour une application 32 bits.
NoyauLe noyau de Haiku est un noyau monolithique tout à fait classique pour un système UNIX. Il permet le chargement dynamique de modules, et fournit une API relativement stable pour ces derniers, ce qui permet de maintenir des pilotes facilement en dehors du dépôt de sources de Haiku.
Correction de problèmes causant le kernel panic « failed to acquire spinlock for a long time » lorsque l’affichage à l’écran des logs du noyau est activé.
Ajout d’assertions supplémentaires dans le code de gestion de la mémoire virtuelle pour essayer de détecter des problèmes au plus tôt et avant de risquer de corrompre des données importantes.
Correction de l’affichage des paramètres des appels systèmes dans strace sur x86.
Correction de problèmes dans la gestion des permissions pour write_stat (modification des informations sur un fichier comme la date de modification) dans le noyau ainsi que dans les systèmes de fichiers RAMFS, BFS et EXT4. Cela corrige des comportements étranges observés lors de l’utilisation de rsync.
Ajout d’un test vérifiant le bon fonctionnement des exceptions remontées par le FPU lors de calculs en virgule flottante (ces exceptions sont un peu difficiles à traiter dans un système multitâche, et en particulier dans Haiku où le code du noyau peut lui-même utiliser le FPU alors que ce n’est pas le cas pour d’autres systèmes).
Correction de problèmes liés au découpage et au redimensionnement des areas (zones de mémoires allouées par les APIs prévues à cet effet de BeOS, ou indirectement par mmap et d’autres fonctions permettant de manipuler l’espace mémoire). Cela corrige des problèmes pour RAMFS ainsi qu’un kernel panic observé lors du lancement de dosemu.
Correction de problèmes avec les areas en lecture seule, qui pouvaient aboutir dans certains cas à une sous-évaluation de la mémoire utilisée, aboutissant à un kernel panic, car il n’y a plus de mémoire disponible à un moment où le noyau ne s’y attend pas. Cela a été mis en évidence en particulier avec l’utilisation mémoire de certains navigateurs web, qui ont tendance à gérer la mémoire directement sans passer par l’allocateur standard du système, pour des raisons de performance.
Remise en route de guarded_heap (un allocateur mémoire qui détecte les dépassements de buffers, au prix d’une consommation mémoire fortement augmentée). Correction de problèmes mis en évidence par cet allocateur dans quelques pilotes.
Dans la structure mcontext/ucontext passée aux fonctions de traitement de signaux, ajout de plusieurs registres manquants (registres de segments, addresse de faute…). Cela est utilisé par le JIT de dosemu et va probablement permettre d’utiliser le JIT dans d’autres applications également. En effet, une approche possible pour le JIT est de déclencher volontairement un signal, afin d’intercepter l’état des registres, éventuellement de le manipuler, puis de reprendre l’exécution là où elle s’était arrêtée.
Ajout de vérification de permissions manquantes dans l’appel système get_extended_team_info.
Correction d’une possible fuite d’un descripteur de fichier dans le VFS.
BootloaderMise à 0 de tous les registres non utilisés lors de l’appel de fonctions du BIOS, afin d’aider à investiguer des problèmes avec certains BIOS capricieux.
Amélioration des messages d’erreurs lorsque le bootloader ne parvient pas à charger le fichier ELF du noyau. Le chargeur de fichiers ELF du noyau est volontairement incomplet pour simplifier les choses (après tout, il a besoin seulement de charger le noyau), mais cela pose problème lors de mises à jour de GCC ou lors du portage sur de nouvelles architectures, si l’organisation du fichier ELF du noyau se trouve modifiée.
Correction de problèmes de compilation lorsque des logs de debug optionels sont activés.
DocumentationLa documentation de Haiku se découpe principalement en trois parties:
Documentation de la classe BControl (classe abstraite qui fournit l’API standard de la plupart des contrôles utilisables dans l’interface graphique, les rendant interchangeables dans une certaine mesure).
Documentation de AdoptSystemColors et HasSystemColors pour la classe BButton.
Ajout de documentation pour les extensions à dlfcn.h par rapport à ce qui est déjà spécifié par POSIX.
Environnement de compilationHaiku est écrit en C++ et utilise jam (un concurrent de make) comme outil principal de compilation. Cet outil a été retenu, car il permet de définir des règles de compilation génériques et réutilisables pour faire toutes sortes de choses. La compilation de Haiku pouvant mettre en jeu trois compilateurs différents (un pour le système hôte, un pour le système Haiku cible, et un troisième pour la couche de compatibilité avec BeOS), la plupart des autres outils ne répondent pas bien aux besoins.
Suppression de règles Jam redondantes. Jam repose sur des règles nommées pour savoir quelles actions sont nécessaires pour générer une cible à partir de sources. Les règles “Application”, “Server”, “Preferences” et “Executable” étaient toutes identiques, elles ont donc toutes été remplacées par “Application” pour simplifier le système de build.
Correction de “warnings” du compilateur pour des variables inutilisées et suppression de code mort (dans le cadre du maintien d’un code propre et lisible, une tâche plus ou moins continue pour suivre l’évolution des bonnes pratiques, la disponibilité de nouveaux outils d’analyse, et absorber la dette technique qui peut s’accumuler au cours d’un projet aussi ancien).
Début de support pour GCC 15: il est ajouté dans la liste des versions du compilateur reconnues pour le système hôte, ce qui permet de compiler Haiku depuis un système Linux très récent. L’intégration en tant que compilateur cible viendra plus tard.
Remplacement de la commande which utilisée dans certains scripts de build par l’équivalent command -v, ce qui évite une dépendance à une commande non standard qui n’est pas forcément installée par défaut partout.
Dans le makefile engine (un template de makefile proposé pour développer facilement des applications pour Haiku), ajout de documentation et d’exemples pour les variables INSTALL_DIR et TARGET_DIR.
Portage de Haiku sur d’autres CPUs RISC-VCorrection d’un problème dans un script de link qui empêchait le démarrage du noyau.
Mise à jour de paquets utilisés pour compiler le système de base.
Mise en place d’un serveur de compilation de paquets pour RISC-V, ce qui permet de remplir le dépôt de paquets pour cette architecture et d’envisager une version officielle de Haiku pour RISC-V lors de la prochaine version bêta. L’architecture RISC-V s’ajoutera ainsi au x86 (32 et 64 bit) déjà supporté.
Télécharger ce contenu au format EPUBCommentaires : voir le flux Atom ouvrir dans le navigateur
Google a annoncé qu'à partir de 2027, seules les applications signées par des développeurs « vérifiés » par Google pourraient s'installer sur les systèmes Android certifiés. Si ce plan est réalisé, il sera impossible de distribuer une application Android sans donner ses données personnelles à Google, et Google pourra interdire à n'importe qui de distribuer des applications Android.
Non. Il est vrai que pour distribuer des applications à travers le Play Store, il faut se faire valider par Google. Par contre, il est possible de distribuer sans l'accord de Google des applications par d'autres canaux, par exemple à travers les plates-formes indépendantes comme F-Droid, ou simplement en mettant une application à disposition sur une page web.
Ça ne concerne que les systèmes Android certifiés, qu'est-ce que ça veut dire ?Android consiste de deux parties : la partie libre, nommée AOSP, et les Google Mobile Services (GMS). AOSP est libre, et n'importe quel constructeur peut donc l'utiliser. Les GMS sont propriétaires, et pour avoir le droit de les distribuer, un constructeur doit obéir à un certain nombre de règles et se faire certifier par Google.
Comme la plupart des applications propriétaires ne fonctionnent pas sans les GMS, la quasi-totalité des systèmes Android distribués dans le commerce sont certifiés.
Qu'est-ce que ça entraîne pour les distributions alternatives d'Android ?Les distributions alternatives d'Android (LineageOS, e/OS, CalyxOS, GrapheneOS, etc.) sont basées sur AOSP, et ne dépendent pas de la certification. Elles pourront donc continuer à autoriser l'installation des applications des développeurs non-validés.
Qu'est-ce que ça entraîne pour les applications libres ?Les développeurs d'applications libres ne pourront plus faire installer leur logiciel sans l'autorisation de Google. Pour certains, ça ne changera probablement pas grand chose, pour d'autres, ça confinera leurs applications aux distributions alternatives d'Android.
Par contre, ça compliquera la contribution au logiciel libre : un contributeur à une application ne pourra plus tester ses changements sur un système Android du commerce, sauf s'il a accès aux clés privées validées par Google.
Télécharger ce contenu au format EPUBCommentaires : voir le flux Atom ouvrir dans le navigateur
Cette revue de presse sur Internet fait partie du travail de veille mené par l’April dans le cadre de son action de défense et de promotion du logiciel libre. Les positions exposées dans les articles sont celles de leurs auteurs et ne rejoignent pas forcément celles de l’April.
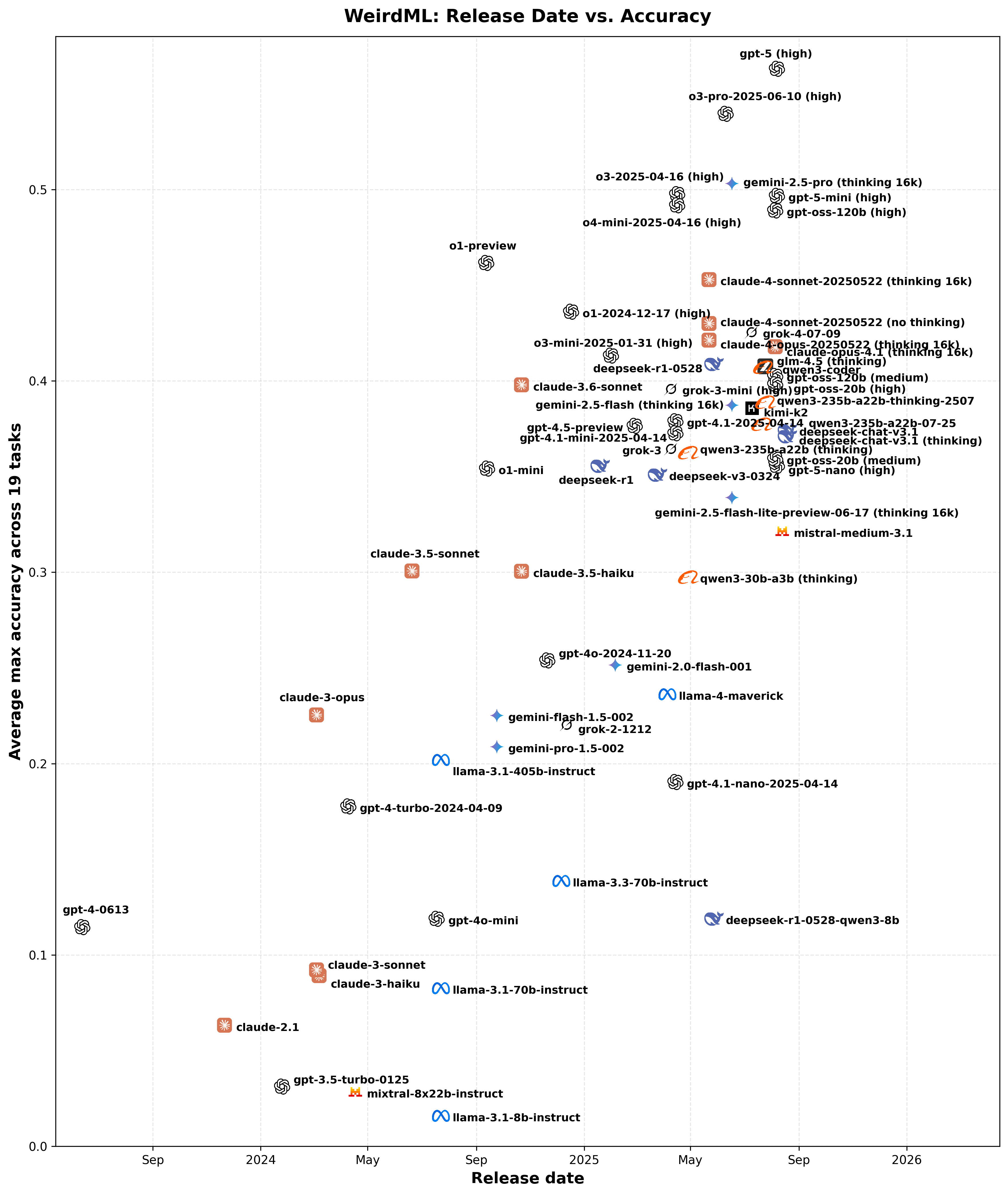{kind=link}
{kind=link}
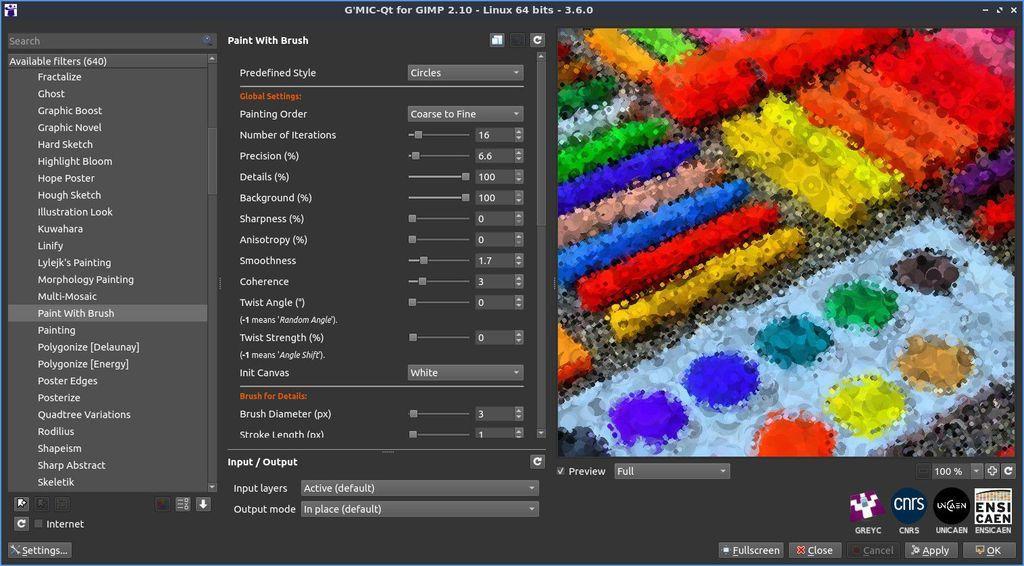{kind=link}
{kind=link}
{kind=link}
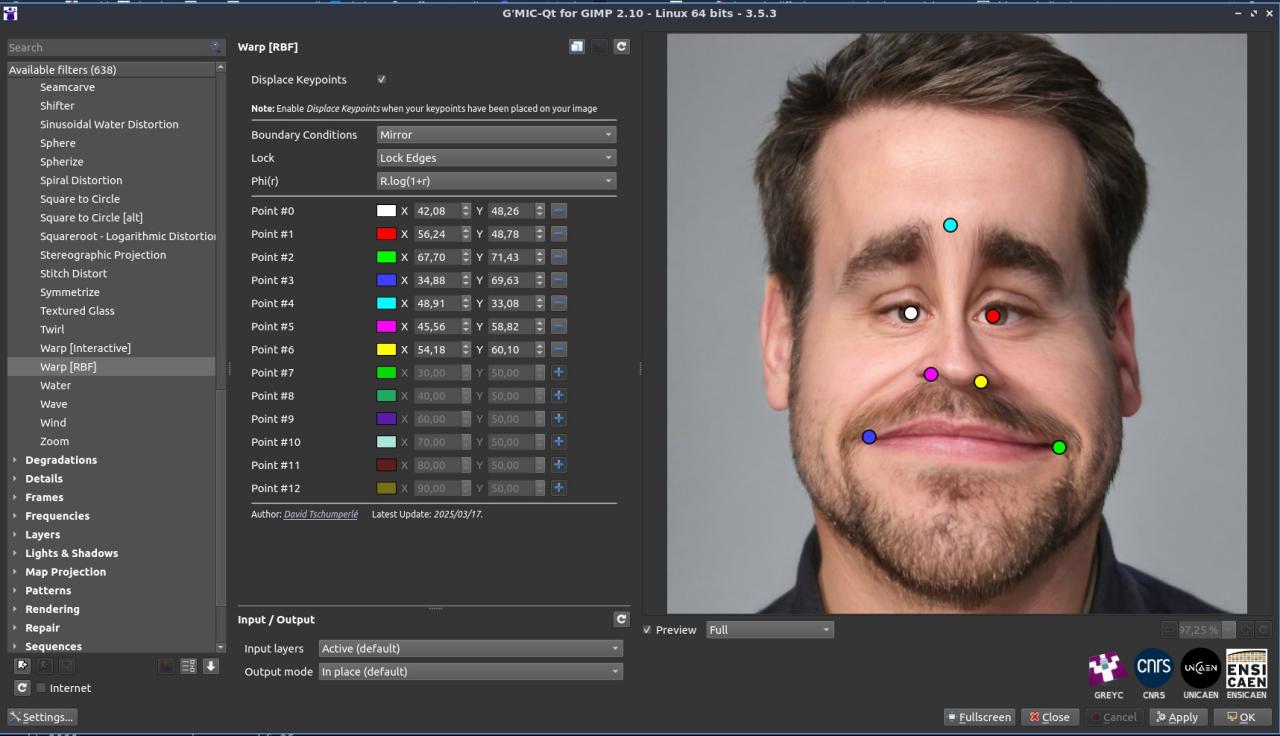{kind=link}
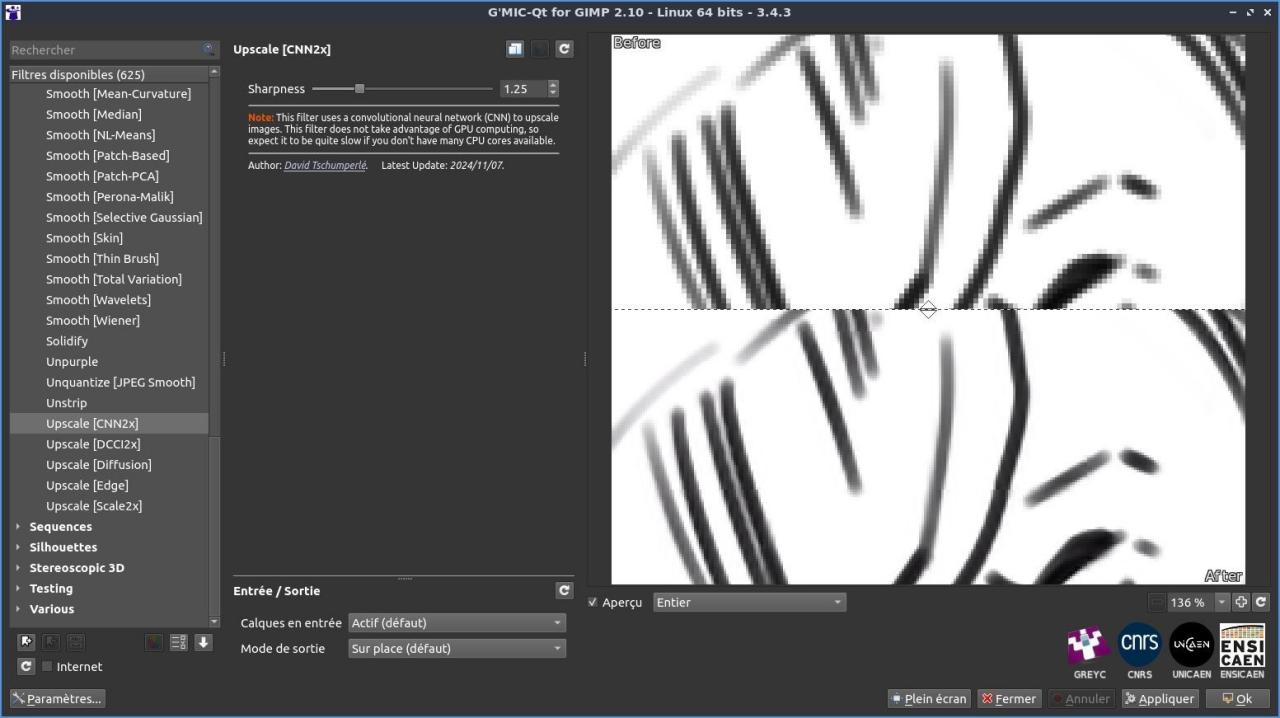{kind=link}
{kind=link}
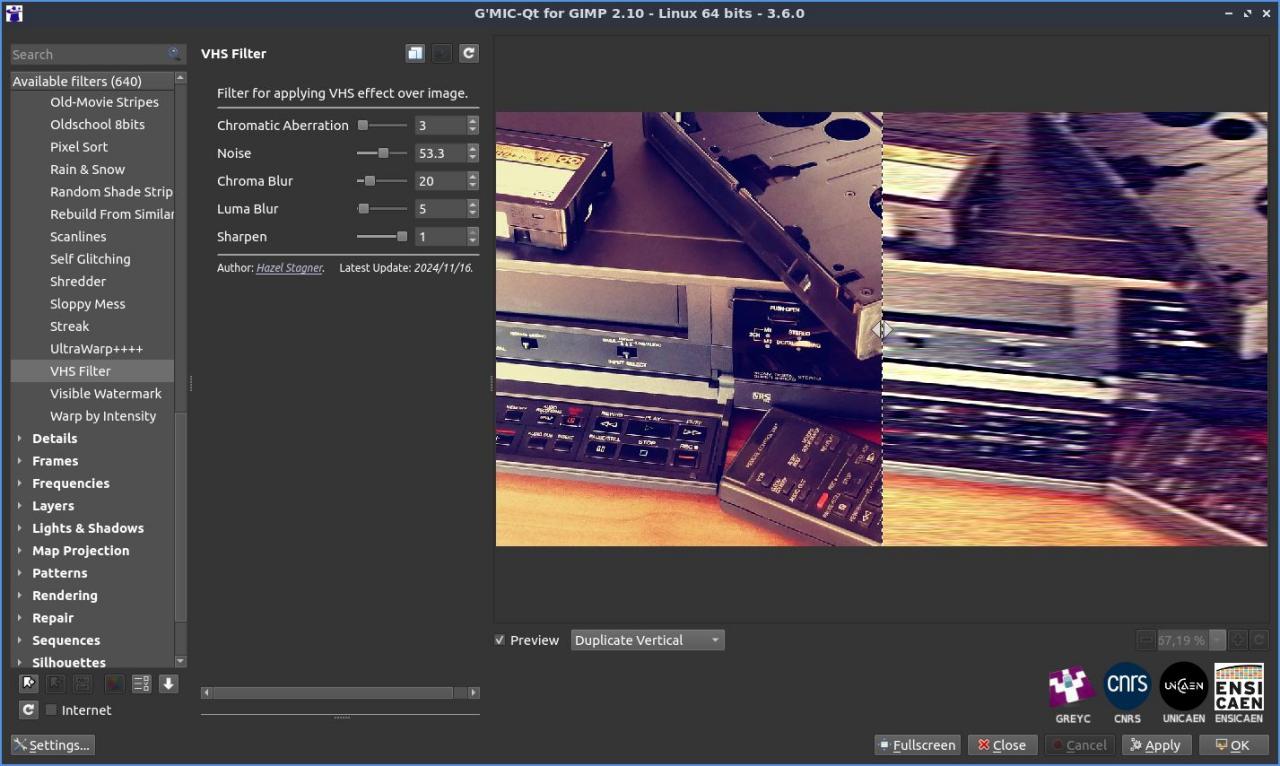{kind=link}
{kind=link}
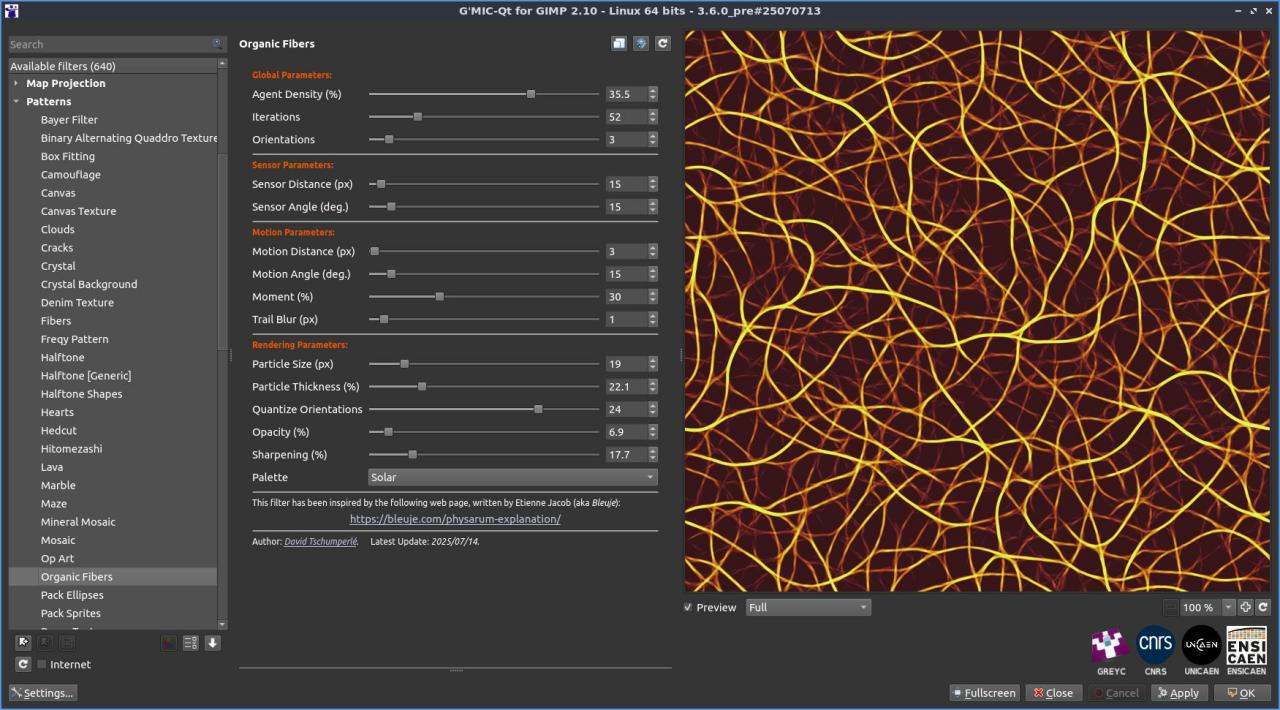{kind=link}
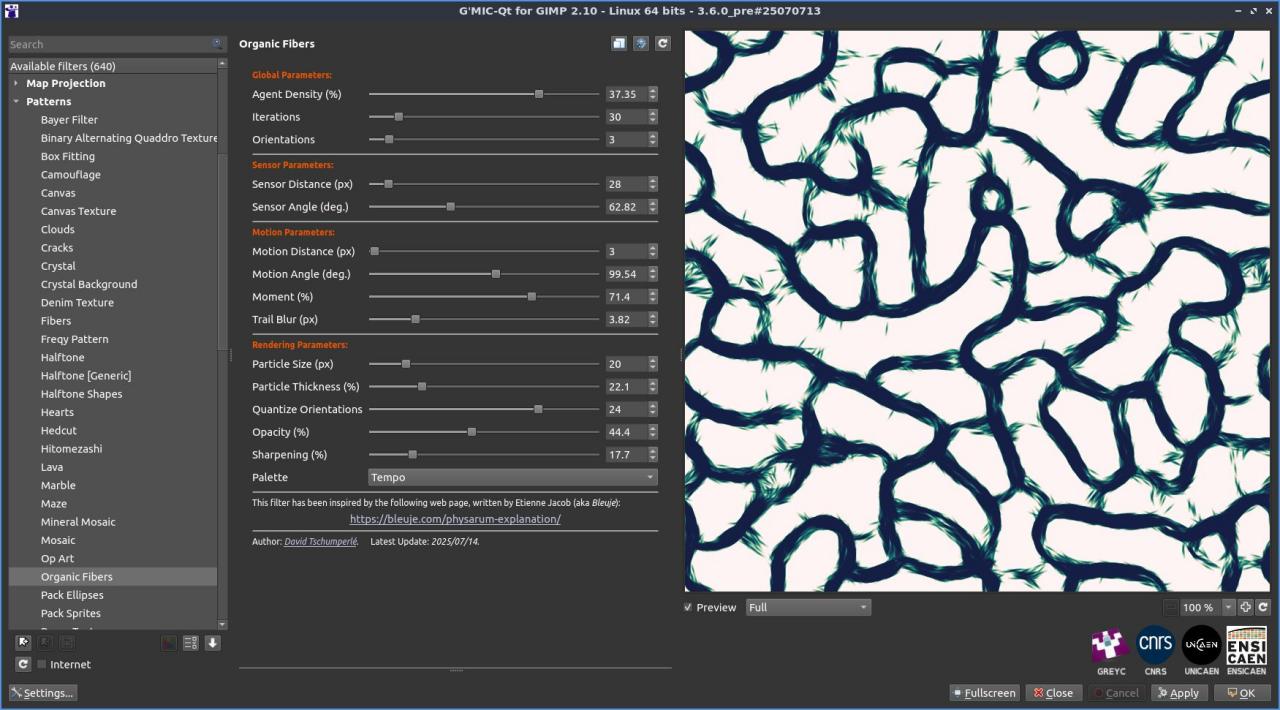{kind=link}
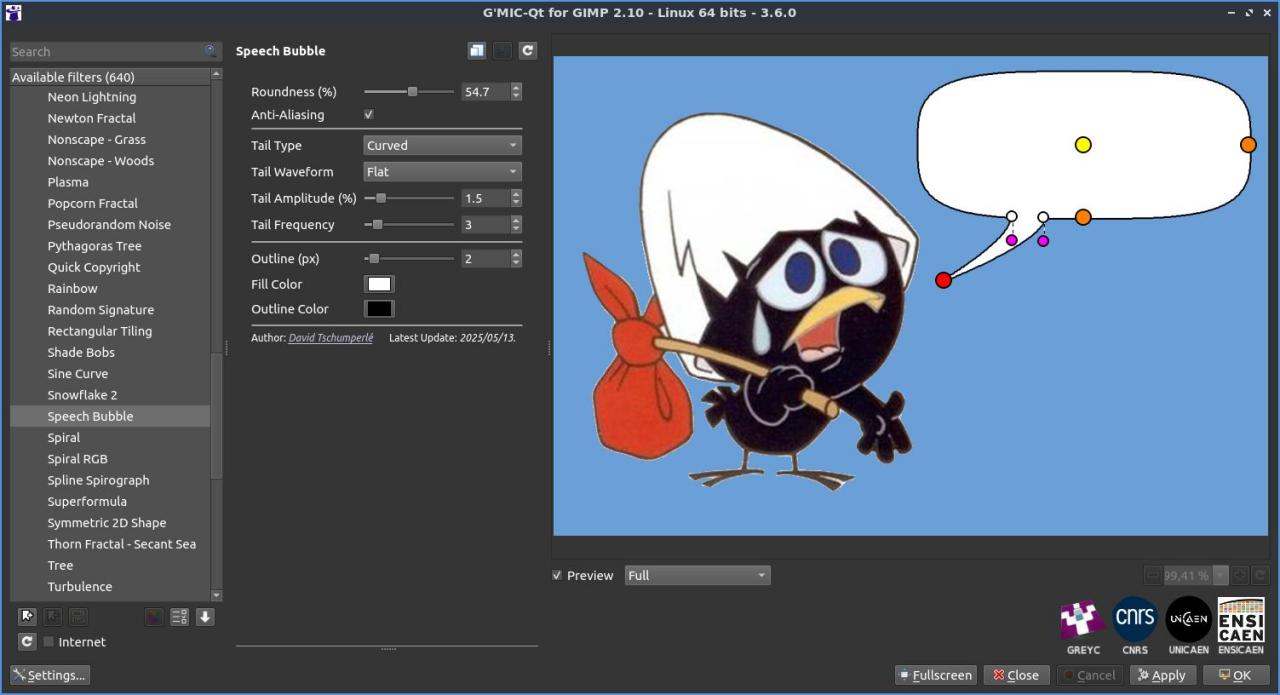{kind=link}
{kind=link}
{kind=link}
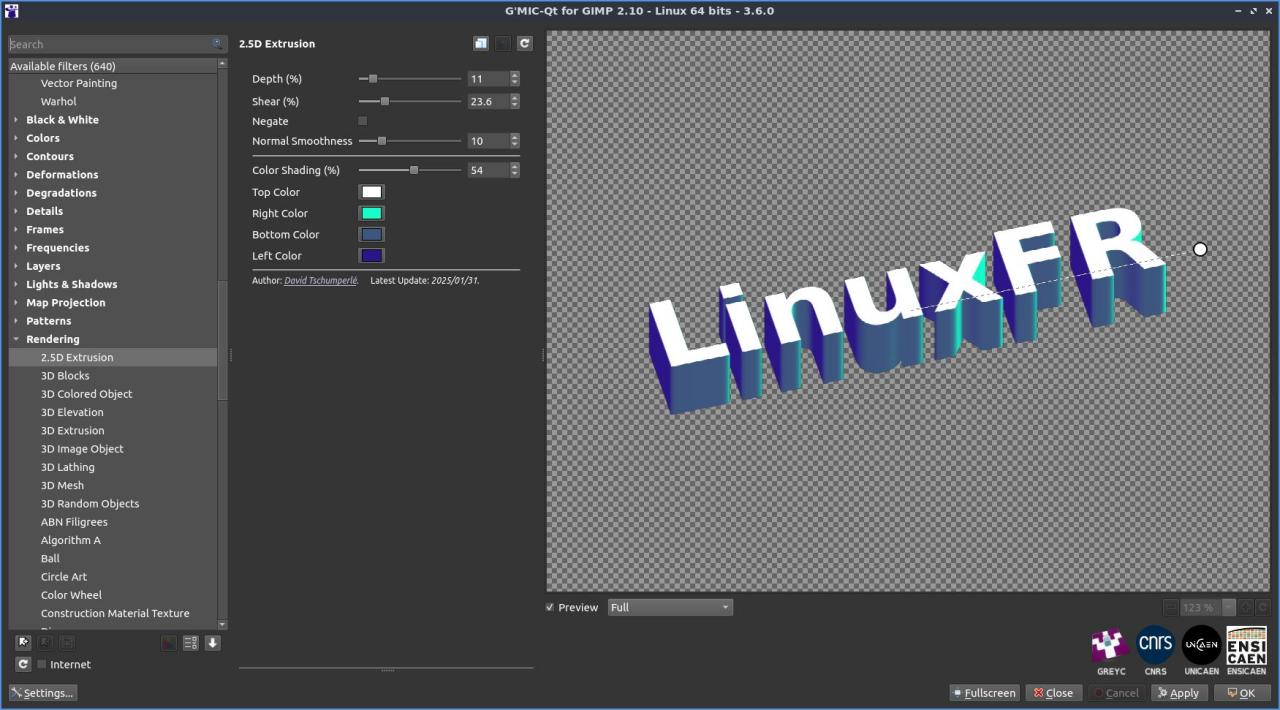{kind=link}
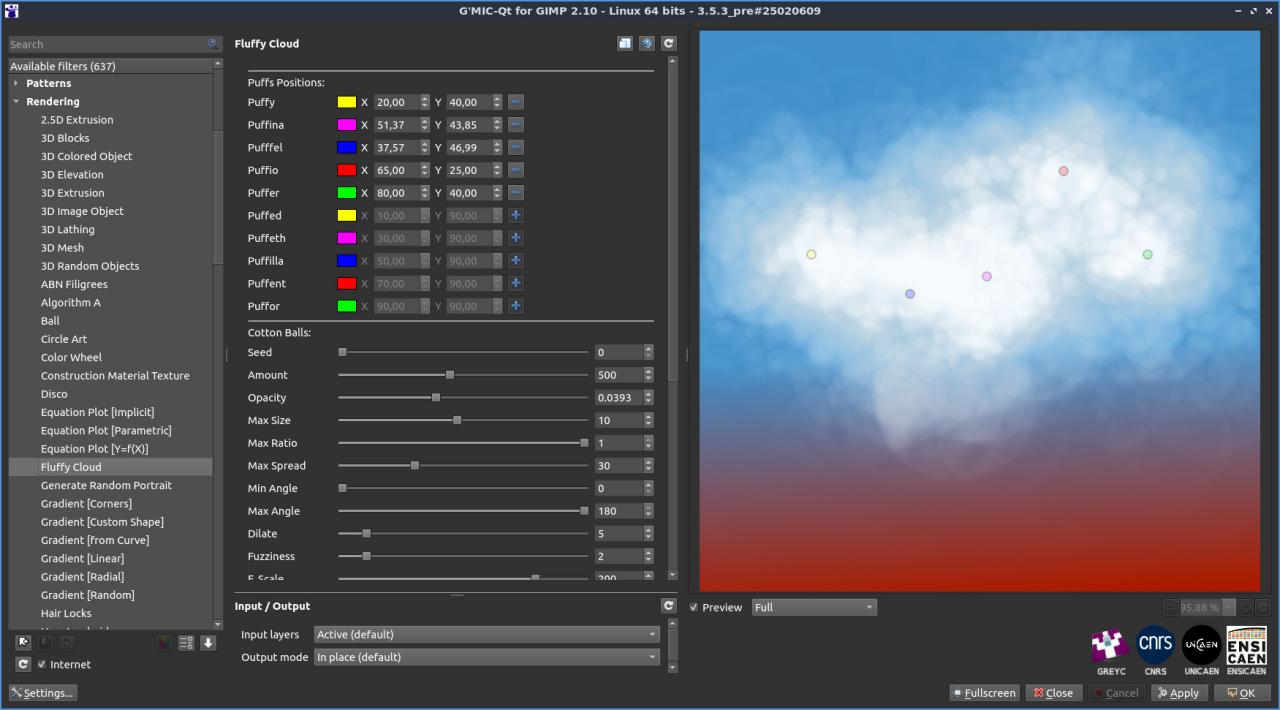{kind=link}
{kind=link}
{kind=link}
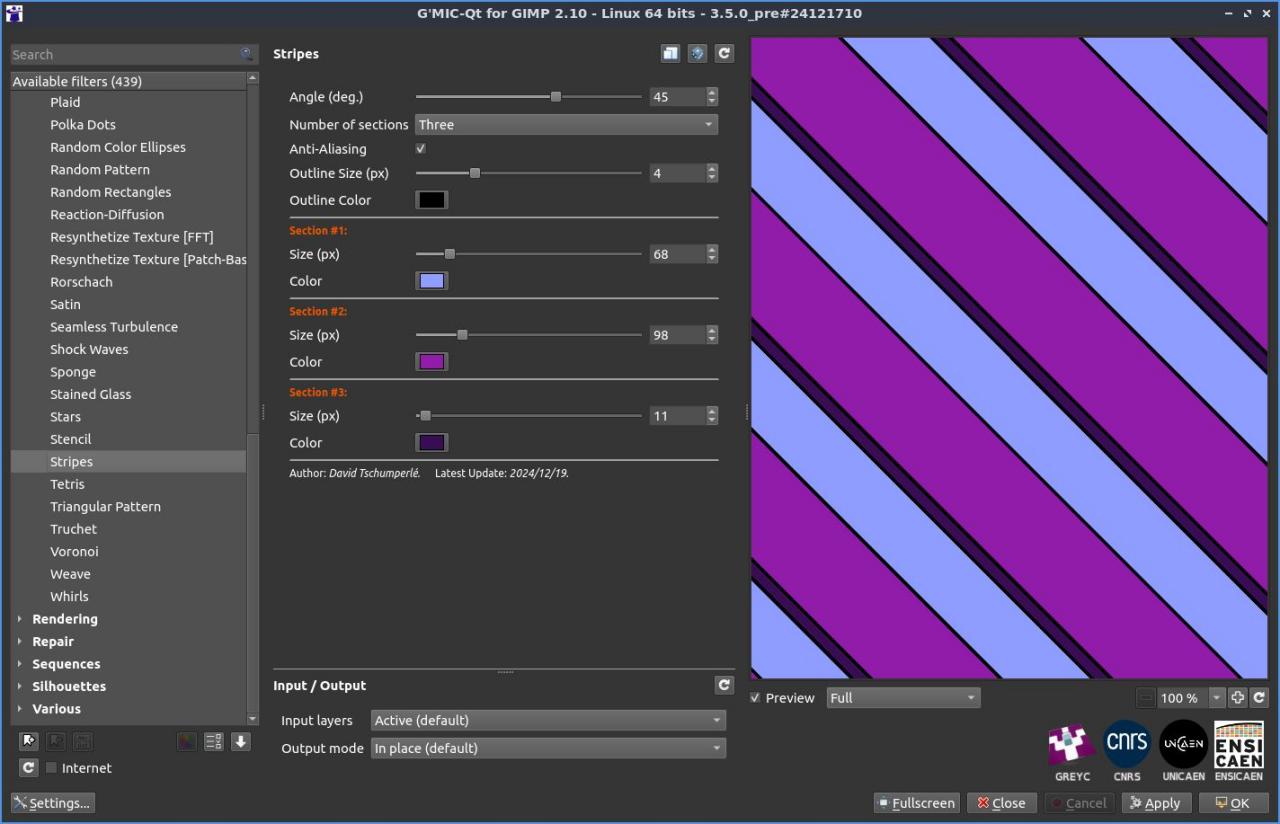{kind=link}
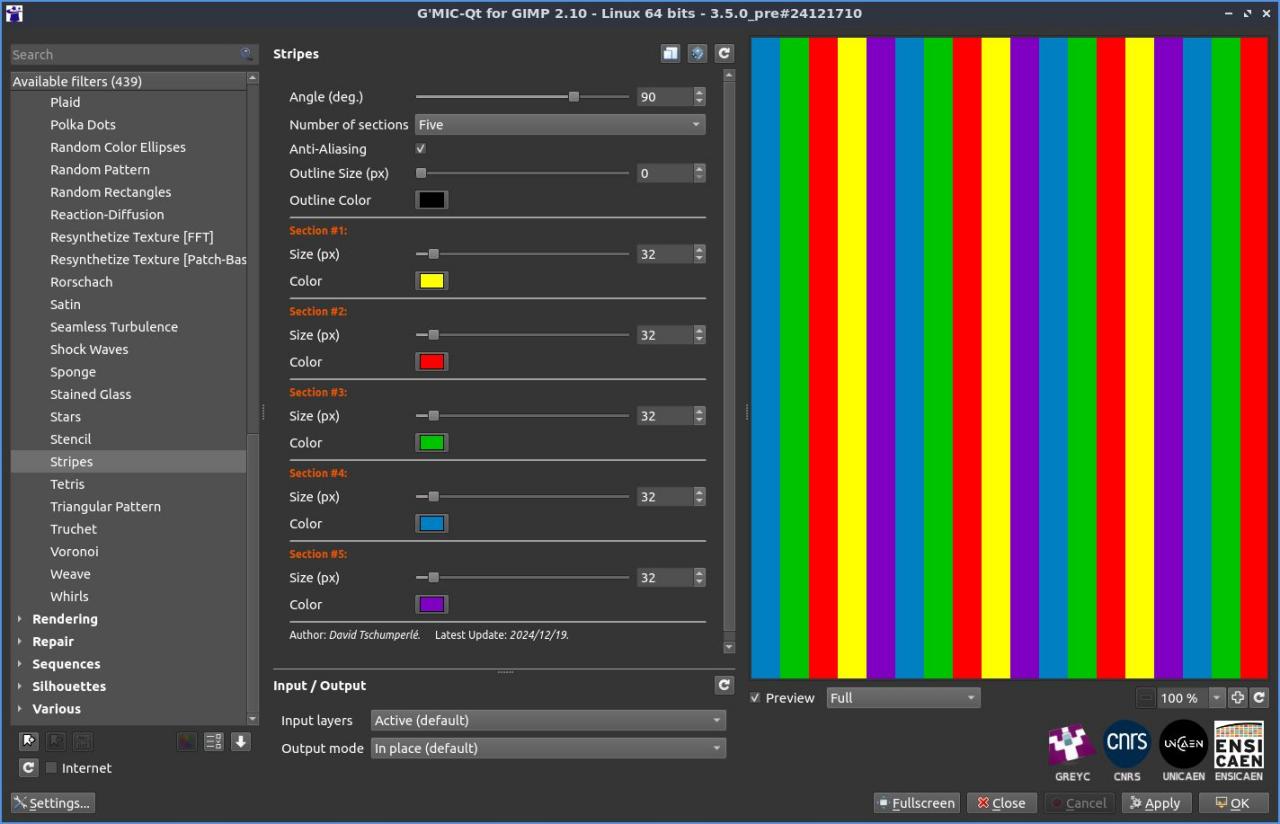{kind=link}
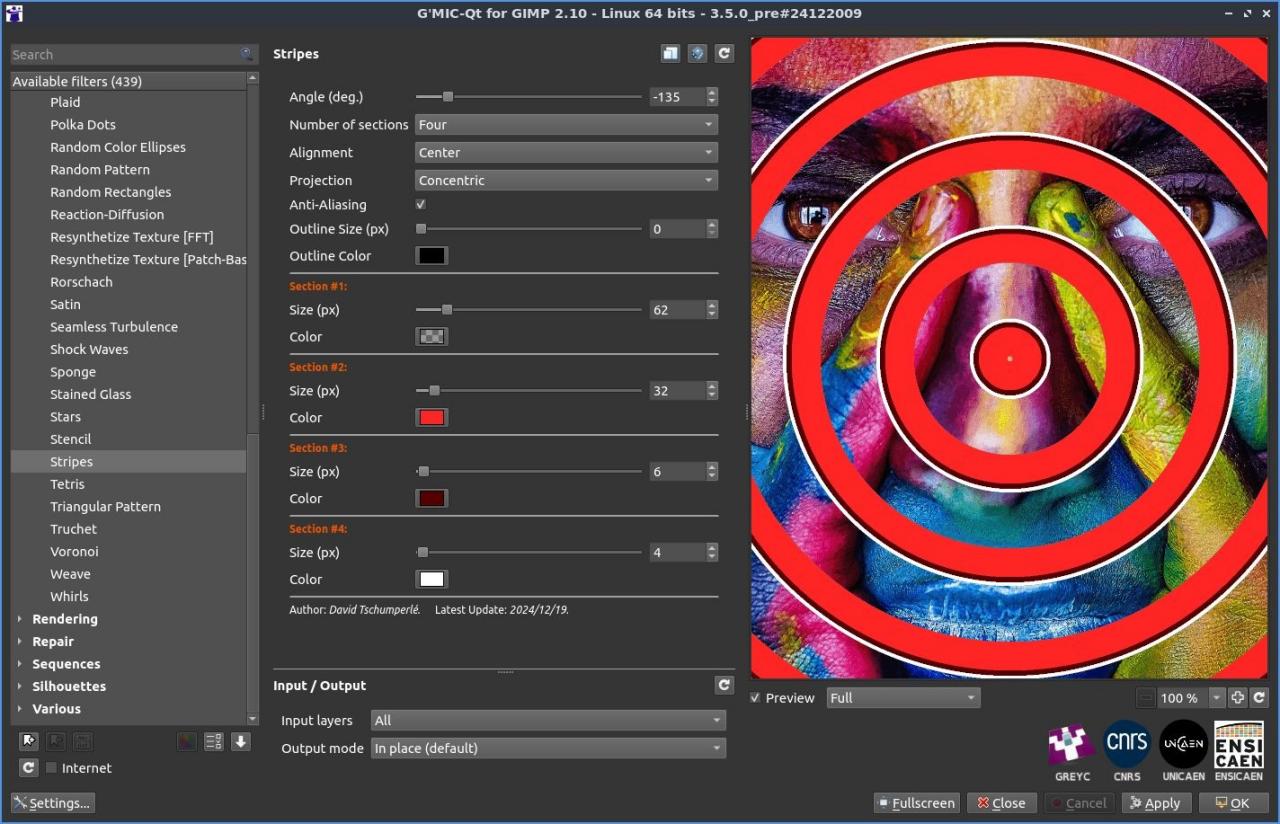{kind=link}
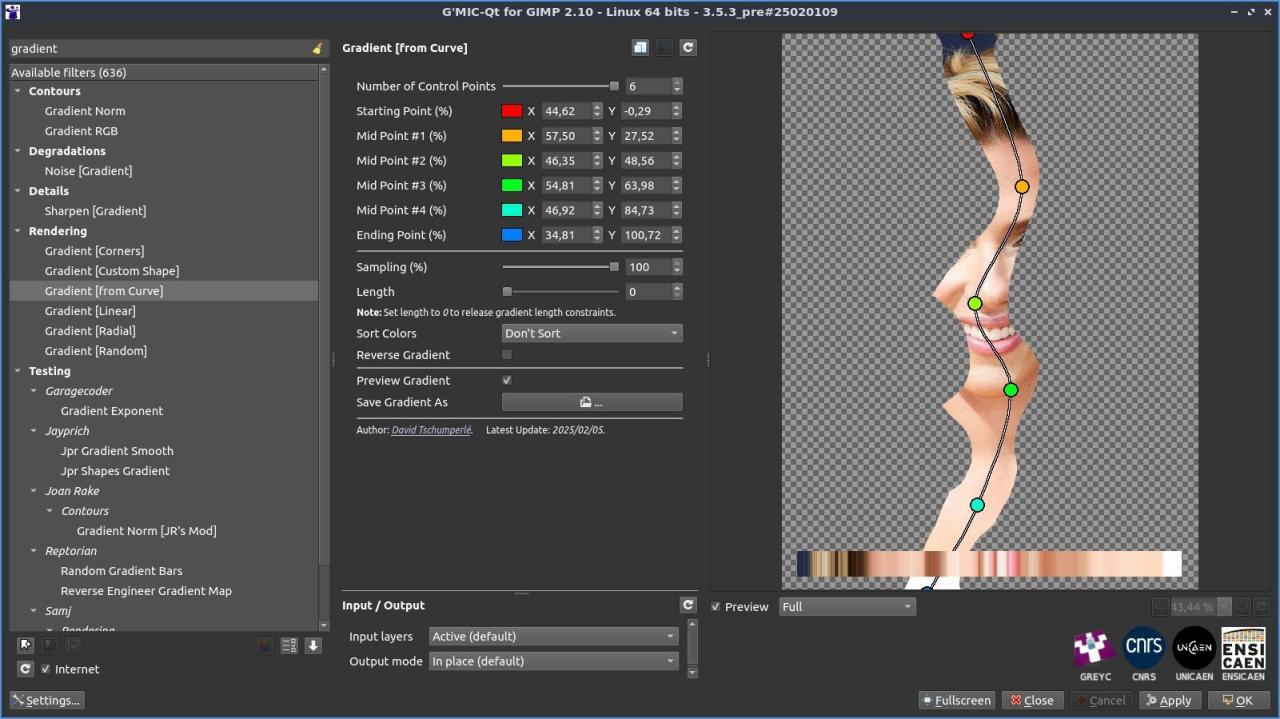{kind=link}
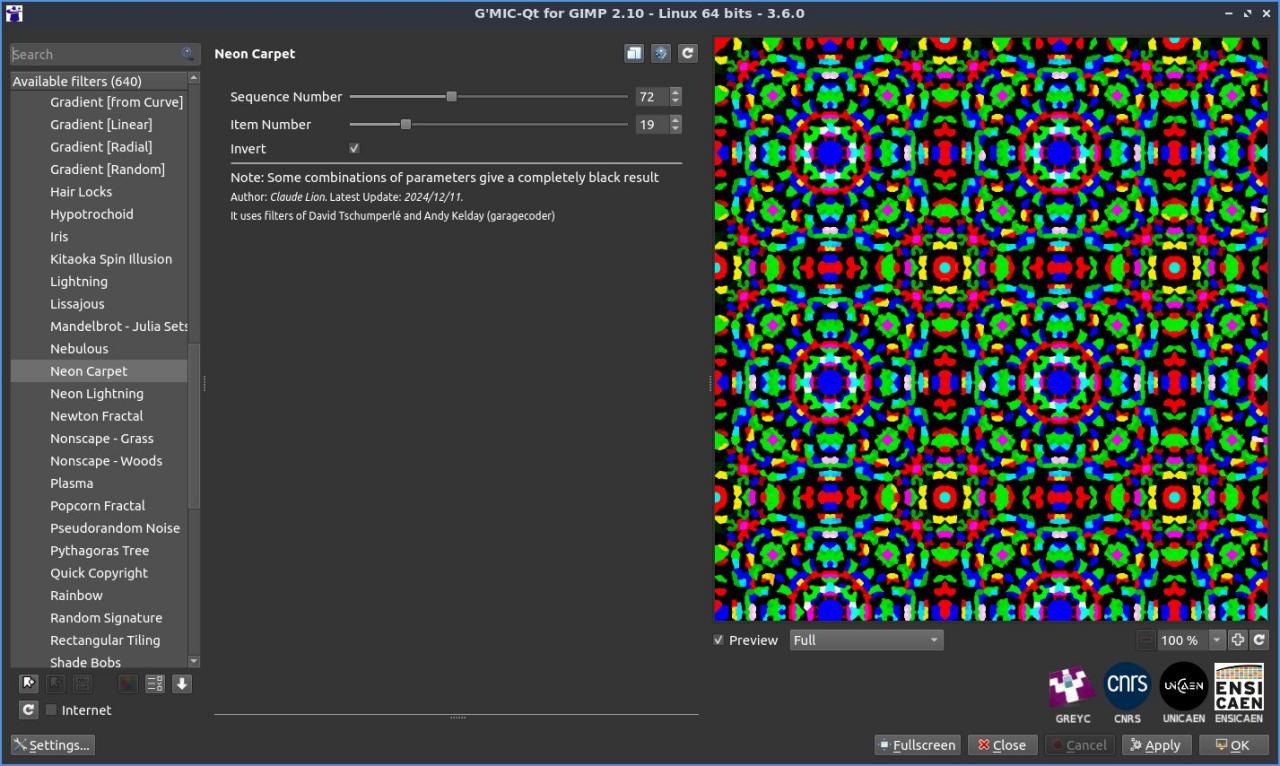{kind=link}