Projet de Confédération de Ressources et de moteur de recherche transversal par Vincent Calame
Submitted by lallorge on 26 janvier, 2008 - 14:24

Conférence : Projet de Confédération de Ressources et de moteur de recherche transversal par Vincent Calame
Conférence donnée lors de l'assemblée générale de l'association April pour la promotion et la défense du logiciel libre en janvier 2008.
Le fichier complet de la conférence : april_ag2008_conf08.ogg (75 Mo) au format Ogg/Theora
Retrouvez aussi cette vidéo sur Dailymotion et sur Youtube.
- Réalisation : Lionel Allorge
- Durée : 10 m 55 s
- Date : 26 janvier 2008
- Langue : Français
- Licence : Creative Commons license by-sa et Art Libre
Transcription
Vincent Calame : Je vais vous présenter un des logiciels que je développe avec la FPH, donc il s'appelle Scrutari, c'est du latin qui veut dire « fouiller ou examiner soigneusement ». Cela montre un moteur de recherches comme confédération de ressources.
La première chose c'est : « Pourquoi un moteur de recherche ? »
Parce que cela peut paraître un peu présomptueux de vouloir en développer un sachant le succès de Google, par exemple. Alors il y a plusieurs raisons. Première raison, c'est au fond, quand on fait une base de données où il y a beaucoup de métadonnées : le titre, les auteurs et ainsi de suite… Ensuite vous le transformez en page web et même si c'est du XHTML même si c'est bien formé, même si c'est bien… Ensuite c'est le moteur de recherche qui passe et le moteur de recherche, finalement il s'en fiche de vos métadonnées il a ses propres algorithmes, ses propres technos donc finalement votre travail, notamment l'indexation par des mots-clefs, il le gère ou il ne le gère pas mais il s'en fiche un petit peu. Donc ça c'est la première raison, pour mettre en valeur ces efforts-là.
La deuxième, c'est définir l'algorithme, maîtriser l'algorithme du moteur de recherche.
On ne confie pas ça à des choses qu'on ne connaît pas et notamment sur lequel on joue sur la pertinence. Un moteur de recherche qui est dédié à votre site web, vous avez pas envie que… Si la personne va rechercher un ou des mots importants de votre sujets, donc si vous êtes dans le Logiciel Libre, de taper logiciel, vous avez envie qu'à la première… au premier résultat qui apparaisse, ce soit la page consacrée vraiment à la définition du Logiciel Libre et pas la page d'archive d'un forum parce qu'il se trouve que l'algorithme a décrété que ce serait la première.
Or c'est important dans une recherche, les cinq premiers résultats sont importants et donc on a envie, quand même, d'avoir un certain contrôle là-dessus.
Et donc après, la troisième raison c'est complémentaire avec un moteur de recherche classique dans le sens où le moteur de recherche Scrutari ne cherche que sur les métadonnées. Il ne fait pas du plein texte, puisqu'on est à la limite, on n'a pas les moyens non plus, d'être concurrents de Google.
Alors ensuite, le deuxième terme dont j'ai parlé : c'est un moteur de recherche comme confédération de ressource.
Je vais un peu définir ce qu'on entend par là. Au début c'est des sites qui ont chacun leur identité, qui composent des ressources documentaires. Donc le cas échéant, un site ressource… nous on a ''comme il est né'', qui est consacré aux notions de la paix, un autre qui est sur les notions de gouvernance et de politique publique, plus d'autres en préparation. Donc, là, chacun a sa propre identité, sa propre ''terminographie'', donc on part de ça. Mais il y a l'idée quand même d'introduire la transversalité entre eux puisqu'un site qui va parler de la paix, va parler de questions politiques. Un site qui parle de la gouvernance, va parler des questions de paix. Nous, on a envie que l'internaute ait accès de façon transversale à ces différentes informations. Avec l'idée d'avoir dans le cadre d'une confédération de ressource une charte rédactionnelle commune en disant : « on essaie d'avoir une information honnête, subjective mais honnête ». Et notamment la partie d'indexation qui dit que si on a un moteur de recherche dont on connait l'algorithme, si on l'ouvre à tous, on a envie de dire qu'on va trafiquer parce qu'on veut à tout prix être dans les premiers résultats alors qu'en fait là non. On estime que ceux qui participent à l'opération de retour s'engagent à indexer proprement leurs informations et à ne pas tricher.
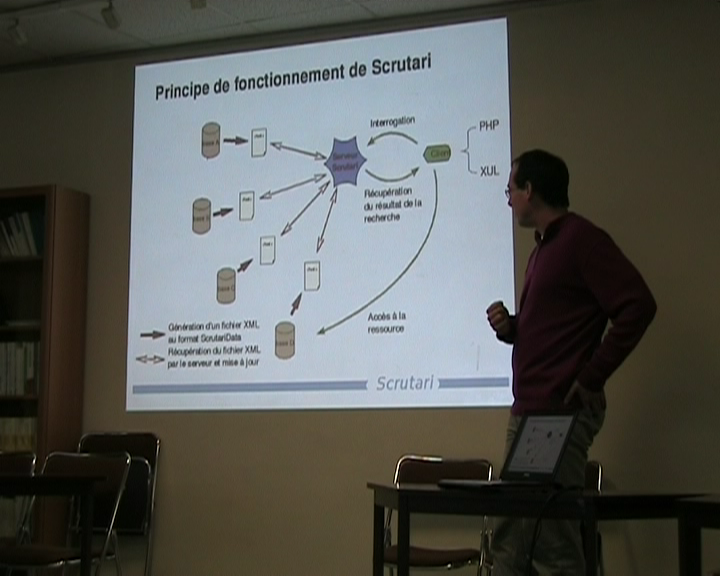
Cette confédération se donne deux types d'outils communs : un wiki, mais je n'en parlerai pas cette fois-ci et donc le moteur de recherche transversal. Le schéma de fonctionnement est relativement simple, il est très proche des flux RSS d'une certaine manière puisqu'au début on a des bases, dans des formats ou des logiciels différents, qui génèrent à intervalles réguliers des formats XML enfin… un format qui nous est propre : Scrutari Data, présentent : voilà quelles sont les ressources importantes de mon site, avec quels mots-clefs, quelles sont mes métadonnées, les champs complémentaires et ainsi de suite. Il y a un serveur qui passe régulièrement pour se mettre à jour, il lit ces différents fichiers présentés, sur ce schéma c'est ce processus. Et après vous avez les clients, pour l'instant on en a deux de développés, un en PHP qui lui s'adapte aux chartes graphiques des sites et un autre qui est en XUL et là qui est équipé d'une interface un peu plus intelligente pour la recherche et le client, lui, de façon classique, va interroger le moteur, le serveur qui va récupérer les résultats et dans les résultats, il y a l'adresse de la ressource complète et là, dans ce cas-là, il retourne à la base de départ pour la consulter. Voilà le schéma.
Ensuite, dernière raison, ou pourquoi je fais cette présentation, parce qu'on cherche à [NdlT: incompréhensible pour cause de grosse toux] à une seule personne, bon… C'est libre que de nom, là on veut monter une communauté un peu autour, questionner ce logiciel par rapport à d'autres expériences.
Donc d'abord discuter du principe, discuter des algorithmes là-dessus et également, sur les clients, on est très preneurs de remontées, du type d'utilisations. Encore de faire des utilisations dans d'autres contextes nous intéresserait également.
Après, deuxième partie, comme pour les flux RSS, il y a en fait des logiciels de gestion de contenu qui produisent et ont tous un module de gestion de flux RSS, de la même manière, développer à terme pour les célèbres logiciels de gestion de contenu un module qui génère un système de format qui nous intéresse.
Puis après c'est un peu dans l'idée où l'April est aussi un lieu d'éducation populaire aussi, un peu ouvert, on va dire,de solliciter vos retours d'expérience, etc. sur la question de la recherche de la formation et également sur les questions de traitements sémantiques. Ça c'est un points qui m'intéresse énormément. Et également toute la question du web sémantique, que je suis assez peu et qui m'intéresse.
Voilà.
Tangui Morlier : Est-ce que c'est utilisé en dehors de la FPH ? Est-ce que vous avez des contributeurs externes ou est-ce que pour l'instant vu la jeunesse du projet ce n'est pas encore le cas ?
Vincent Calame : Bon pour l'instant, au niveau du développement, il n'y a que moi, donc il n'y a pas de contributeur externe. Après, moi j'ai des partenaires de la FPH qui avaient déjà leur site, notamment deux personnes c'était sous SPIP qui ont faites des petites… J'ai mis comme sous XML et ils ont fait le petit programme qui génère les données et qui les renvoie au serveur. Mais à chaque fois c'est lié purement… Enfin c'est pas vraiment un module, sous SPIP, ils l'ont fait pas rapport à leurs propres données. Moi ce qui m'intéresserait c'est d'avoir un module…
Tangui Morlier : Plus générique.
Vincent Calame : Plus générique quelque soit les différents logiciels de gestion de contenu.
Thomas Pettazoni : Il y a une question, par rapport à l'échelle du projet, parce que la question m'intéresse dans le sens où quand je fais une recherche pour quelque chose, j'ai pas vraiment envie d'aller chercher dans beaucoup d'endroits différents, je préfère un seul endroit centralisé qui lui va me permettre de rechercher dans une grande partie d'Internet. Là ou je [NdlT : incompréhensible] c'est qu'une fois qu'il y a un grand nombre de sites qui sont ''indexables'', un très grand nombre d'acteurs, en général il y a des problèmes, la charte que tu présentais au début :"pas de tricherie dans l'indexation" a espoir d'être bafouée car c'est internet qui… Vu ce qu'il se passe sur Internet. Donc comment est-ce que tu penses que cela pourrais grandir de façon globale ?
Vincent Calame : Je pense qu'il y a l'idée de créer des architectes de structure de toute confiance vers le problème. Moi j'utilise aussi Google mais il y a une telle masse de bruit et d'information, on parie sur le fait… Pour moi où il y a une certaine formalité… Ou en tout cas on est capable de remonter aux auteurs et ainsi de suite. Et on offre un lieu où à l'intérieur de ce lieu, les gens sont engagés à vouloir une certaine fiabilité, qualité de l'information. Donc c'est un peu un pari dans l'idée de la confédération de ressource, c'est sûr qu'il y aura toujours utilisation de Google mais… C'est un peu comme proposer, dans tout site, il y a une partie recherche. La question c'est soit on la confie à Google aussi, on peut très bien chercher son propre site et dans ce cas là on se lave complètement les mains de cette partie-là. Soit on se dit qu'on va quand même faire un effort sur ce moteur de recherche, pour que ce soit une information un peu pertinente.
Jean Montagné : Dans une problématique similaire, moi j'ai pensé à me tourner vers les logiciels de bibliothèques, tout simplement. Est-ce que vous avez exploré cette voie et qu'est-ce qui vous différencierait ?
Vincent Calame : Ben non, je pense qu'on ne se différencie pas… C'est indépendant… Le but c'est d'être indépendant du logiciel de départ dans lequel est saisie l'information. Donc si quelqu'un a un logiciel de bibliothèque, on peut ressortir ces métadonnées de la même manière.
Jean Montagné : Et dans un logiciel de bibliothèque, il y a aussi l'aspect catalogue, c'est-à-dire une fois que les données sont indexées, dans un format bibliothécaire, on peut ressortir les données à chacun.
Vincent Calame : Je n'ai jamais utilisé ces logiciels…
Tangui Morlier : Vous pourrez continuer peut-être pendant le…
Vincent Calame : Oh oui, de toute façon c'est la dernière.
Tangui Morlier : Merci.
Applaudissement


Inscrivez-vous aujourd'hui à l'infolettre pour découvrir les enjeux du logiciel libre, des outils et des moyens d'actions. Prenez le contrôle de vos libertés informatiques. Suivez nos actions en cours et à venir.








